Kafka Connect
Access control
User permissions to Kafka cluster resources are defined by Connect actions. See: User Authorization.
Configuration
Kafka Connect
The following connects to a standard Kafka Connect cluster using the standard REST API.
Kpow connects to a Connect cluster with environment variables.
| Variable | Description |
|---|---|
| CONNECT_NAME | UI and logs friendly name for this connect |
| CONNECT_STARTUP_VALIDATION | (Optional) Validate that the Kafka Connect server is reachable at startup. When set to false, and Kpow cannot reach the host, an error message will be displayed in the UI, and Kpow will attempt to reconnect to the specified host. Default: true |
| CONNECT_REST_URL | The client connection URL for your connect cluster |
| CONNECT_AUTH | BASIC if basic authentication is configured |
| CONNECT_BASIC_AUTH_USER | Username if basic authentication is configured |
| CONNECT_BASIC_AUTH_PASS | Password if basic authentication is configured |
| CONNECT_OFFSET_STORAGE_TOPIC | (Optional) Topic that holds connect offsets |
| CONNECT_GROUP_ID | (Optional) Unique string identifying worker cluster group |
| CONNECT_PERMISSIVE_SSL | True if SSL certificate validation should be disabled |
| CONNECT_TIMEOUT_MS | The timeout value in ms for all HTTP requests made to a Kafka Connect cluster. Default: 5000 |
| CONNECT_RESOURCE_IDS | Optional, comma separated list of unique ids. Only specify when configuring multiple connect clusters |
| CONNECT_OBSERVATION_VERSION | Optional, specifies the snapshot version to use. Defaults to 1 |
| CONNECT_SSL_KEYSTORE_LOCATION | Optional, specifies the keystore location to use when connecting to the REST API over SSL. |
| CONNECT_SSL_KEYSTORE_TYPE | Optional, specifies the keystore type when connecting to the REST API over SSL. Example: PKCS12, see KeyStore for more info |
| CONNECT_SSL_KEYSTORE_PASSWORD | Optional, specifies the keystore password when connecting to the REST API over SSL. |
| CONNECT_SSL_TRUSTSTORE_LOCATION | Optional, specifies the truststore location when connecting to the REST API over SSL. |
| CONNECT_SSL_TRUSTSTORE_TYPE | Optional, specifies the truststore type when connecting to the REST API over SSL. |
| CONNECT_SSL_TRUSTSTORE_PASSWORD | Optional, specifies the truststore password when connecting to the REST API over SSL. |
| CONNECT_AUTO_RESTART | Optional, specifies a comma-separated list of connectors to restart when Kpow identifies them as failed. See: auto-restart connectors |
| CONNECT_AUTO_RESTART_WINDOW_MS | Optional, specifies the window between successively attempting to restart a failed connector. Default: 600000 |
| CONNECT_AUTO_RESTART_LIMIT | Optional, specifies the maximum number of failed connectors Kpow will attempt to restart each one-minute interval. Default: 50 |
Configuring multiple connect clusters
Kpow supports multiple Kafka Connect clusters associated to a single Kafka cluster.
To configure multiple Kafka Connect clusters, use the environment variable CONNECT_RESOURCE_IDS to define a comma separated list of Connect clusters. Kpow uses the resource ID as a prefix in the environment variable.
Example configuration when configuring two Kafka Connect clusters:
CONNECT_RESOURCE_IDS=DEV1,QA2
DEV1_CONNECT_REST_URL=http://dev1-connect.mycorp.org:8003
QA2_CONNECT_REST_URL=http://qa2-connect.mycorp.org:8003
In this example we have defined connections to two Kafka Connect resources: DEV1 and QA2
The values for CONNECT_RESOURCE_IDS must be upper-case like DEV1 and not dev1.
The sort order follows the sequence of resource IDs in the CONNECT_RESOURCE_IDS list.
For example, if CONNECT_RESOURCE_IDS=QA1,DEV1,DEV2, the order will be QA1, DEV1, then DEV2.
Observation version
To control how Kpow snapshots Kafka Connect, use the CONNECT_OBSERVATION_VERSION flag to set the observation version.
By default, when CONNECT_OBSERVATION_VERSION is set to 1, Kpow follows a two-step process to capture connect metadata. First, it retrieves all connectors with a single query. Then, with the specified parallelism level, it makes multiple REST calls for each connector: a separate call for task, status and connector information.
This method can be resource-intensive for larger connect clusters, as the number of REST calls increases proportionally to the number of connectors.
Alternatively, when CONNECT_OBSERVATION_VERSION is set to 2 (Kafka Connect only), Kpow uses a single-step process to capture connect metadata. It makes a single REST call to fetch all connectors, including their metadata.
This approach can be much more efficient than version 1, but is only supported by more recent Kafka Connect API versions (version 6.2 and above).
SSL connections
Kpow can connect to the Kafka Connect REST API over SSL. Kpow uses standard TrustStore and KeyStore environment variables to specify the certificates required to make the secure connection over SSL to the Kafka Connect server.
In order for Kpow to connect over SSL you will need to configure your Kafka Connect server appropriately. See KIP-208 for more details.
Refer to the environment variables table above to see the full list of environment variables available.
Example SSL configuration
CONNECT_SSL_TRUSTSTORE_LOCATION=/docker/ssl/my-truststore.jks
CONNECT_SSL_TRUSTSTORE_PASSWORD=password
In the example above we have configured Kafka Connect to use a KeyStore volume mounted at /docker/ssl.
Auto-restart connectors
Kpow offers the ability to automatically restart specified connectors and failing tasks, providing enhanced reliability and uptime for your data integration workflows.
To enable this feature, simply set the CONNECT_AUTO_RESTART environment variable in your configuration.
When activated, Kpow will monitor for failed connectors at one-minute intervals. After attempting to restart a connector, Kpow will wait for the user-configured amount of time before trying again. By default, this interval is set to 10 minutes, but you can adjust it using the CONNECT_AUTO_RESTART_WINDOW_MS environment variable.
Additionally, Kpow allows you to specify a limit on the number of connectors that can be restarted automatically. The default limit is 50 connectors, but you can modify this setting using the CONNECT_AUTO_RESTART_LIMIT environment variable. This feature helps prevent excessive restart requests being sent to the Kafka Connect cluster.
All restart attempts will be logged in the audit log as actions performed by the kpow_system user.
If you have configured Kpow's Slack integration, all restart attempts will also be sent to a Slack webhook. This integration enhances real-time monitoring and alerting capabilities, ensuring that your team is promptly notified of any restart actions taken by Kpow.
Note: If the connector is failing more frequently than CONNECT_AUTO_RESTART_WINDOW_MS limit then it may require manual intervention.
Example configuration
CONNECT_AUTO_RESTART="*" # restart all failed connectors
CONNECT_AUTO_RESTART="dbz-connector-1" # restart **only** the connector dbz-connector-1 when it enters a failed state
CONNECT_AUTO_RESTART="mysql-prod-us*" # restart any connector that matches the wildcard (mysql-prod-us-east1, mysql-prod-us-west2, etc)
CONNECT_AUTO_RESTART="payments-*,*-stage" # you can specify many filters by providing a comma-separated list
Connector page
The Connector page offers a detailed view of connectors, plugins, tasks, and their current status, helping you monitor and manage your Kafka Connect environment.
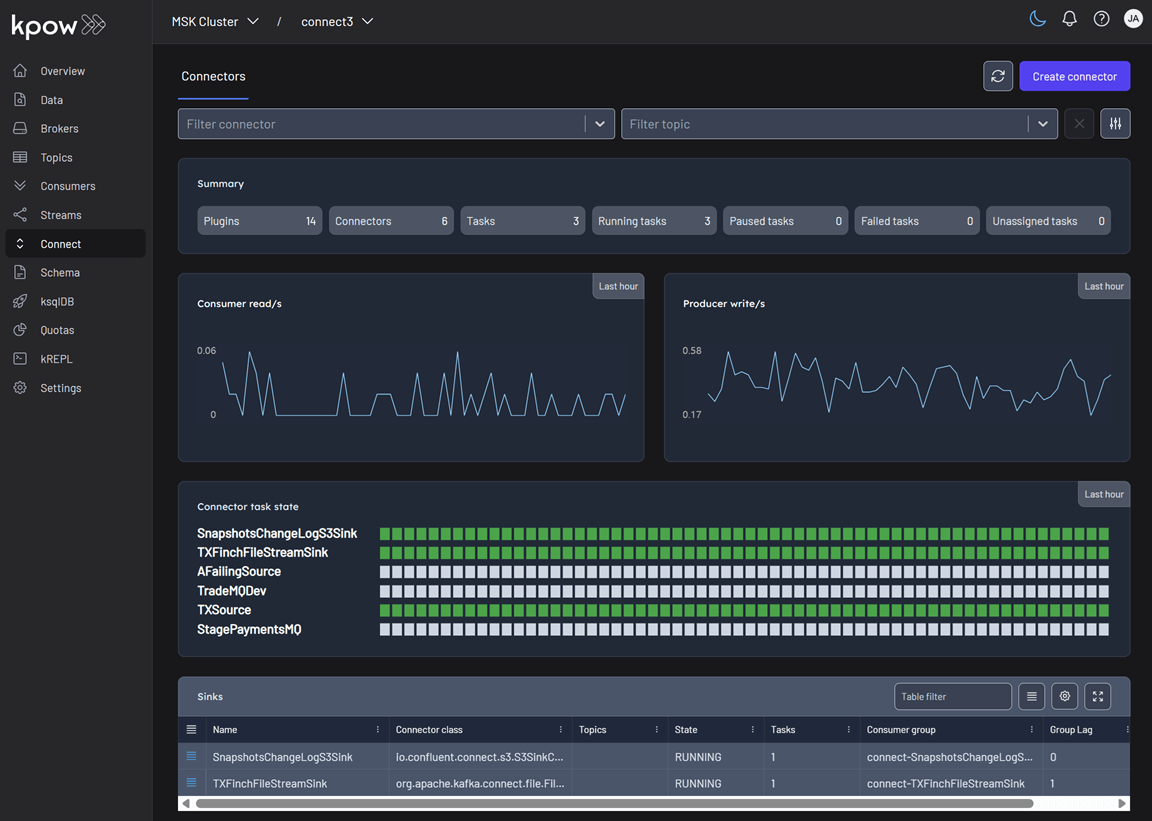
Create connector
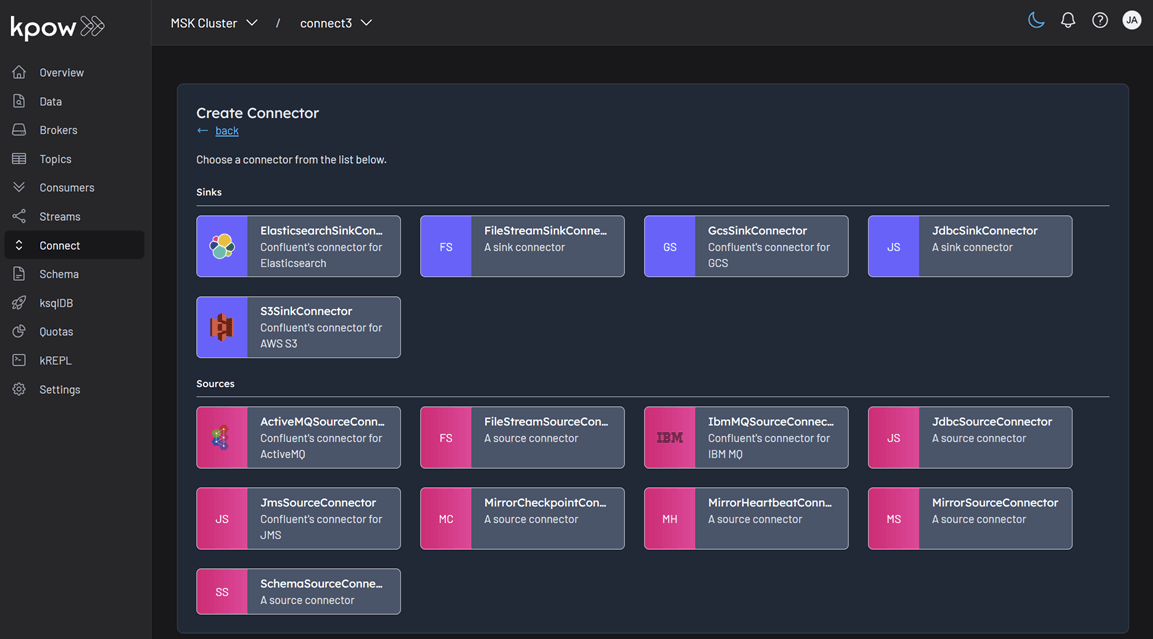
To create a new Kafka connector, start by clicking the Create Connector button.

This opens a list of all available connector plugins, including both source and sink types. Each plugin represents a supported integration for ingesting or exporting data.
You can configure the connector in one of two ways:
- Import a JSON file containing the full connector configuration, or
- Manually enter configuration properties using the provided form.
This flexible setup allows you to quickly get started with a known config or define one from scratch.
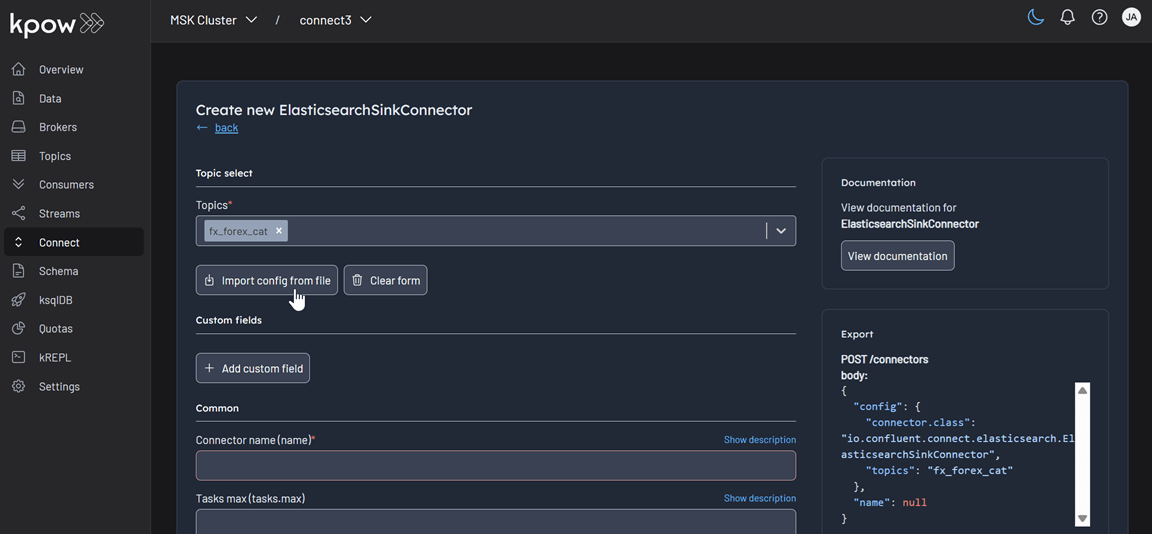
Once configured, the connector can be deployed immediately and will appear in the main Connector view for monitoring and management.
Supported operations
Kafka Connector
Kpow supports a wide range of operations to help manage and troubleshoot Kafka connectors.
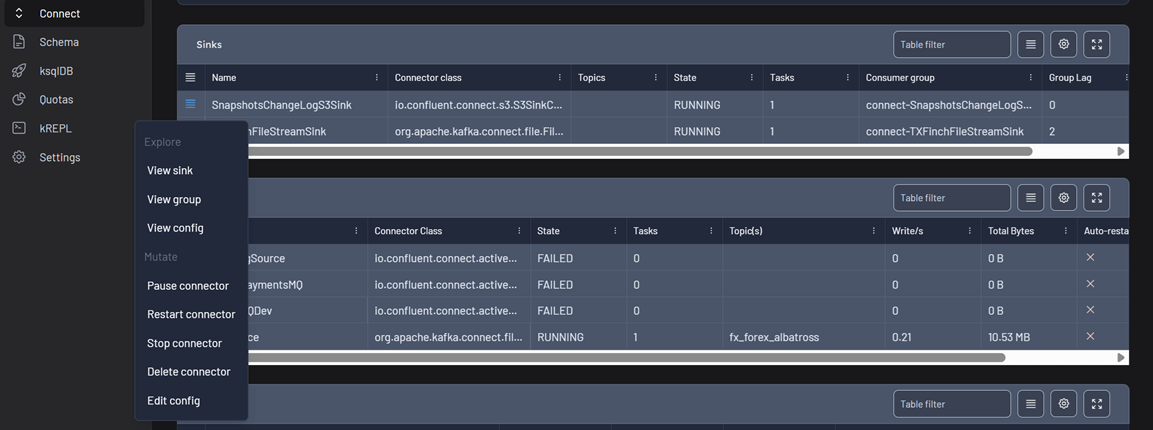
- Explore
- View source (sink) – Filter the selected connector to easily monitor task status and data throughput.
- View group (sink connector only) – Redirect to the consumer group linked to a sink connector.
- View config – Display the current configuration of the connector in JSON.
- Mutate
- Pause connector – Temporarily halt the connector without removing it.
- Restart connector – Restart the connector to recover from failures or apply updates.
- Stop connector – Stop the connector to halt its data processing without deleting it.
- Delete connector – Permanently remove the connector from the Kafka Connect cluster.
- Edit config – Modify the connector's configuration directly.
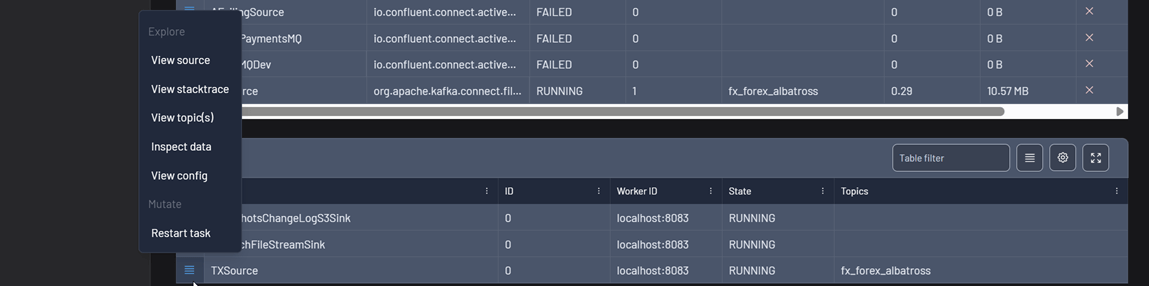
Connector task
Each connector consists of one or more tasks. Kpow allows you to inspect and manage these tasks individually.
- Explore
- View source (sink) – Check the topic associated with the task's data flow.
- View stacktrace – View the latest error stack trace if the task has failed.
- View topic(s) – Display all topics currently assigned to the task for reading or writing.
- Inspect data – Opens the Data Inspect page with all assigned topics pre-selected.
- View config – See the configuration for the individual task.
- Mutate
- Restart task – Restart a specific task, useful for recovering from transient errors.