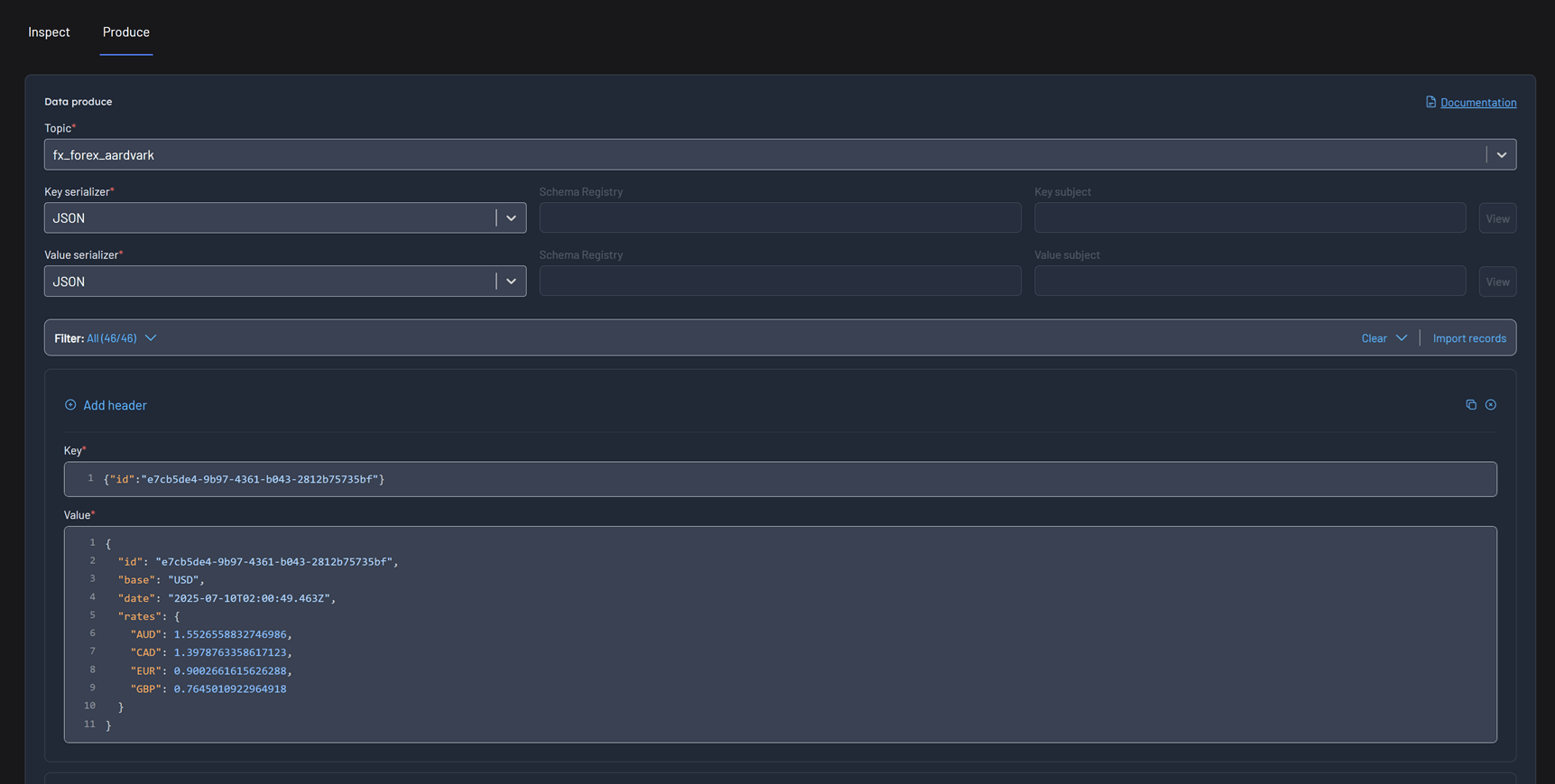
Data produce
Introduction
Kpow's data produce UI allows you to bulk-produce multiple records to a single topic.
The data produce form is idempotent. Once a record has been produced it won't be retried.
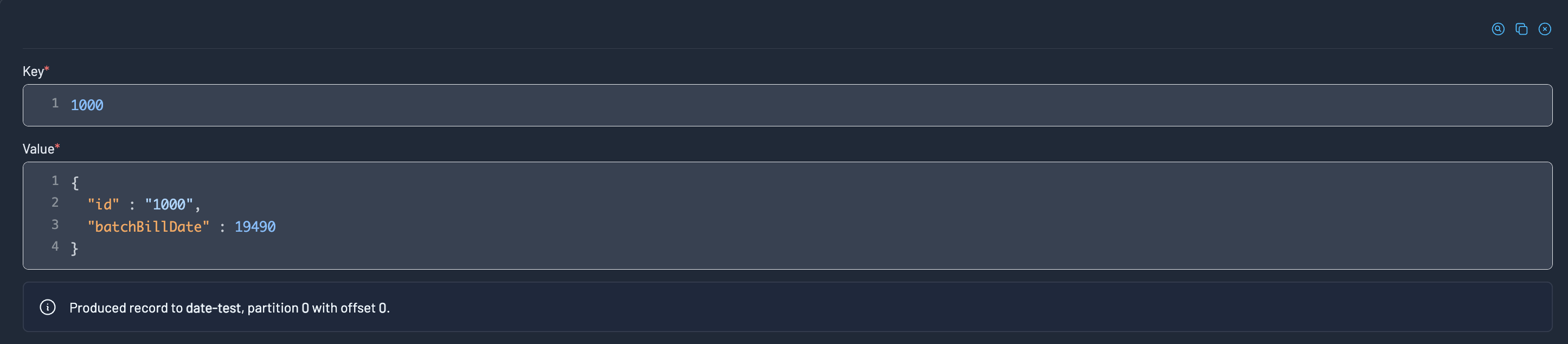
Metadata about the record appears in the footer once it has been produced.
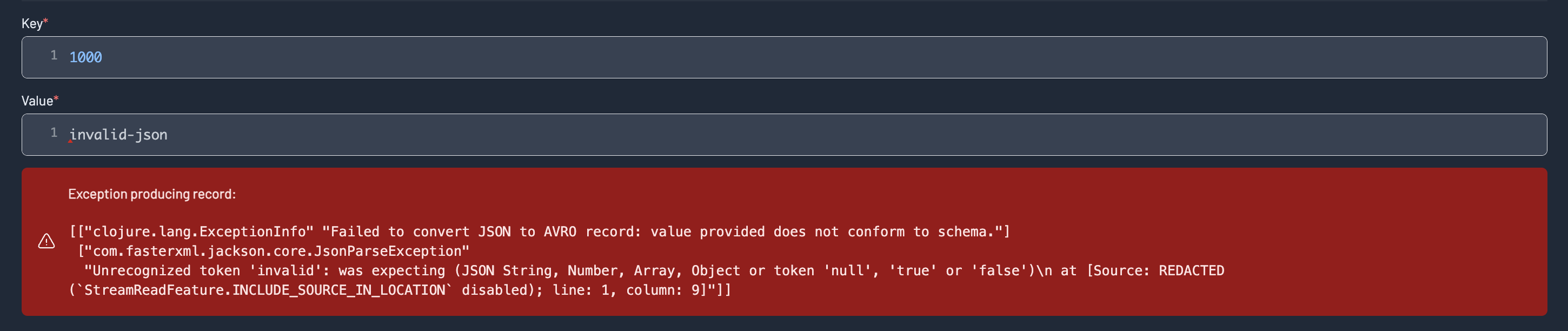
If a record was unsuccessfully produced, information about the error will appear in the records footer:
Use the toolbar to filter down to just erroring records, or clear any produced records from the form:

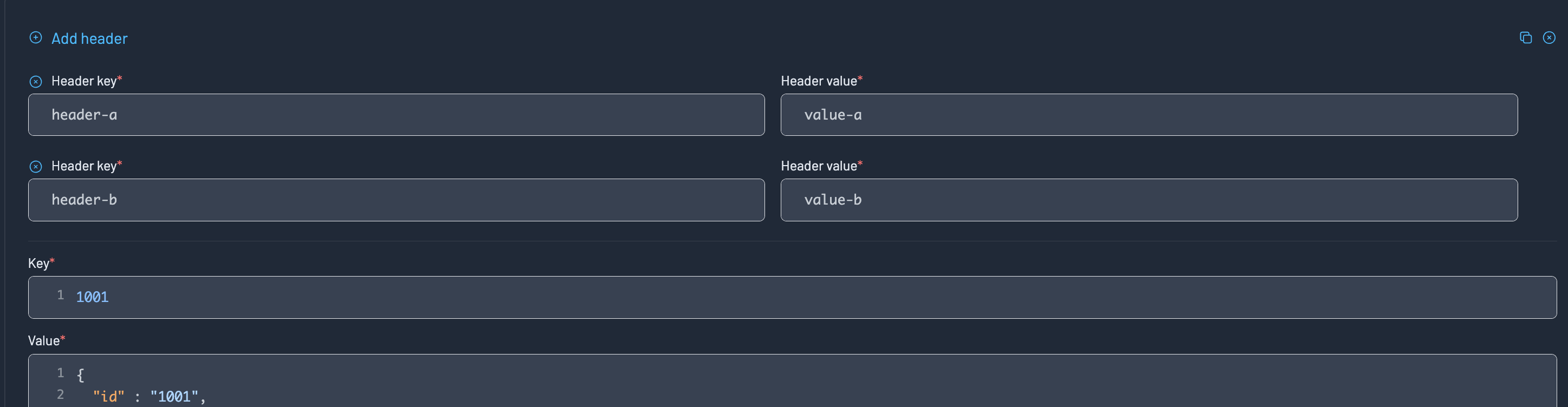
Adding headers
Kpow supports multiple key/value pairs as headers to the record.
Tombstone records
Specify the 'None' SerDes for either the key or value serializer to produce a null key or value.
Specifying 'None' as the value serializer (with a non-null key) will produce a tombstone record.
Importing records
Load records from a CSV, JSON or EDN file into the data produce form by clicking the "Import Records" button on the control pane.
CSV
An example CSV:
"1000","{""name"": ""sam""}"
"1001","{""name"": ""jane""}"
Importing with headers
All remaining columns after the initial key and value column are reserved for headers:
"1000","{""name"": ""sam""}",HeaderKey1,HeaderValue1,HeaderKey2,HeaderValue2
"1001","{""name"": ""jane""}",HeaderKey1,HeaderValue2
JSON
The format for importing JSON is a collection of objects containing key and value keys. The values for the key/value pairs must be a string.
[{
"key": "1000",
"value": "{\"name\": \"sam\"}"
}]
Importing with headers
You can optionally specify a headers key for each record in the array. This must be a map where the keys are strings and the values are arrays of strings.
[{
"key": "1000",
"value": "{\"name\": \"sam\"}",
"headers": {"header1": ["value1", "value2"]}
}]
Headers are structured like this because there can be multiple values for each key in a Kafka records header.
EDN
The format for importing EDN is a collection of maps containing :key and :value keys. The values for the key/value pairs must be a string
[{:key "1000", :value "{\"name\": \"sam\"}"}]
Importing with headers
You can optionally specify a :headers key for each record in the array. This must be a map where the keys are strings and the values are arrays of strings.
[{:key "1000",
:value "{\"name\": \"sam\"}",
:headers {"header1" ["value1"]}}]
Headers are structured like this because there can be multiple values for each key in a Kafka records header.
Producing logical types (AVRO)
Kpow provides built-in support for AVRO logical types such as date and decimal. Here's how to produce these values correctly in the Data Produce UI or via imported records.
Date logical type
For fields declared with:
{
"name": "someDate",
"type": {
"type": "int",
"logicalType": "date"
}
}
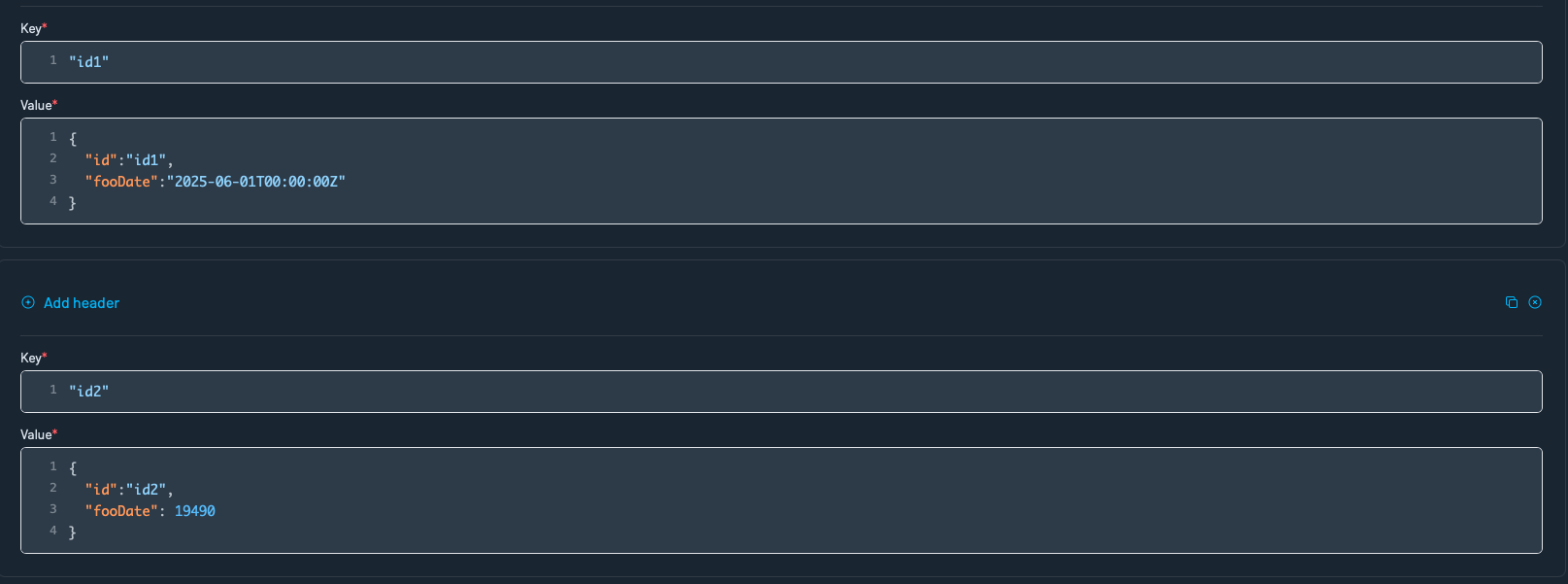
You can provide either:
- An ISO 8601 date string (recommended)
{
"someDate": "2024-05-13T00:00:00Z"
}
Kpow will automatically convert it to the appropriate epoch-day integer.
- A raw epoch day integer
{
"someDate": 19500
}
This is also accepted directly if you already know the number of days since epoch (1970-01-01).
Tip: Kpow uses a custom AVRO date conversion that supports both formats for flexibility.
Decimal logicalType (BigDecimal)
For fields declared like:
{
"name": "amount",
"type": {
"type": "bytes",
"logicalType": "decimal",
"precision": 8,
"scale": 2
}
}
You can provide a decimal string such as:
{
"amount": "1234.56"
}
Kpow will handle conversion to AVRO's decimal binary representation.
Note: AVRO decimal types must be serialized as bytes with appropriate scale and precision. Kpow handles this automatically when a string is provided.
Data inspect
After executing a Data Inspect query, you can click Data Produce in the control pane. This loads the query results directly into the data produce form.

All results from the query are automatically added to the form.