A Practical Guide to Data Lineage on Kafka Connect with OpenLineage
This guide provides a complete, end-to-end solution for capturing real-time data lineage from Kafka Connect. By the end of this tutorial, we will have a fully functional environment that tracks data from a source connector, through Kafka, and into data sinks like S3 and Apache Iceberg, with the entire graph visualized in Marquez.
The core of this solution is the OpenLineageLifecycleSmt, a custom Single Message Transform (SMT) that enables automated lineage without modifying our data records. We will walk through its setup, configuration, and limitations to provide a comprehensive understanding of how to achieve lineage for Kafka Connect pipelines.
Set up the environment
Clone the project
git clone https://github.com/factorhouse/examples.git
cd examples
Start all environments
This project uses Factor House Local to spin up the Kafka and Flink environments.
Before starting, make sure you have valid licenses for Kpow and Flex. See the license setup guide for instructions.
# Clone Factor House Local
git clone https://github.com/factorhouse/factorhouse-local.git
# Download necessary connectors and dependencies
./factorhouse-local/resources/setup-env.sh
# Configure edition and licenses
# Community:
# export KPOW_SUFFIX="-ce"
# export FLEX_SUFFIX="-ce"
# Or for Enterprise:
# unset KPOW_SUFFIX
# unset FLEX_SUFFIX
# Licenses:
# export KPOW_LICENSE=<path>
# export FLEX_LICENSE=<path>
# Start Kafka and Flink environments
docker compose -p kpow -f ./factorhouse-local/compose-kpow.yml up -d \
&& docker compose -p flex -f ./factorhouse-local/compose-flex.yml up -d \
&& docker compose -p obsv --profile lineage -f ./factorhouse-local/compose-obsv.yml up -d
OpenLineage Kafka Connect SMT
While Apache Kafka is not a natively supported integration in OpenLineage, lineage tracking can be enabled for Kafka Connect using the OpenLineageLifecycleSmt Single Message Transform (SMT), which is included in Factor House Local.
The custom SMT enables fully automated, real-time data lineage by emitting OpenLineage events to a compatible backend (such as Marquez). It acts as a pass-through transform: records are not modified, but lifecycle hooks in Kafka Connect are used to capture and report rich metadata about data pipelines.
Supported connectors
The SMT is designed to work with multiple Kafka Connect source and sink connectors. Currently, it supports:
- Source connectors
- Amazon MSK Data Generator (
com.amazonaws.mskdatagen.GeneratorSourceConnector)
- Amazon MSK Data Generator (
- Sink connectors
- Confluent S3 Sink Connector (
io.confluent.connect.s3.S3SinkConnector) - Iceberg Sink Connector (
io.tabular.iceberg.connect.IcebergSinkConnector)
- Confluent S3 Sink Connector (
Datasets creation
The SMT automatically discovers input and output datasets based on the explicit configuration we provide to it.
-
Kafka topic datasets
- Identification: The SMT identifies Kafka topics from the
topicsproperty in its configuration. - Direction: It uses the
connector.classproperty to determine if the topics are inputs (for a sink connector) or outputs (for a source connector). - Namespace and name: For lineage purposes, each Kafka topic is treated as a distinct dataset.
- The dataset name is the topic name itself (e.g.,
orders). - The dataset namespace is the canonical URI of the Kafka cluster, constructed by prepending
kafka://to the bootstrap server address (e.g.,kafka://kafka-1:19092). This ensures consistent identification across different systems like Flink.
- The dataset name is the topic name itself (e.g.,
- Schema: When
key.converter.schema.readorvalue.converter.schema.readis set to true, the SMT connects to the Schema Registry to fetch the latest schema for keys, values, or both. This enables rich, column-level lineage tracking. We must also provide supporting properties like the Schema Registry URL and authentication info.Note: Currently, the SMT's schema parsing logic is implemented specifically for the Avro format. Schemas of other types (e.g., Protobuf, JSON Schema) will not be parsed, and column-level lineage will not be available for those topics.
- Identification: The SMT identifies Kafka topics from the
-
Sink output datasets (S3 & Iceberg) For sink connectors, the SMT creates a one-to-one mapping from each input Kafka topic to a corresponding output dataset in the target system.
-
S3 sink connectors
- Configuration: Requires the
dataset.namespaceproperty. - Dataset namespace: The namespace for the output dataset is set by the
dataset.namespaceproperty (e.g.,s3://fh-dev-bucket). - Dataset names: The names of the output datasets are the names of the input Kafka topics. For example, data from the
orderstopic will be represented as an S3 dataset namedorderswithin the specified namespace.
- Configuration: Requires the
-
Iceberg sink connectors
- Configuration: Requires the
dataset.namespaceanddataset.namesproperties. - Dataset namespace: The namespace for the output dataset is set by the
dataset.namespaceproperty (e.g.,s3://warehouse).- This namespace can be either the logical name (e.g.,
thrift://hive-metastore:9083) or the physical name (e.g.,s3://warehouse). Because the OpenLineage Spark integration reports the physical name by default, using the physical name is recommended for downstream compatibility.
- This namespace can be either the logical name (e.g.,
- Dataset names: The names of the output datasets are determined by the
dataset.namesproperty. Unlike the S3 sink connector, the physical dataset name can be different from the topic name, so the mapping should be specified explicitly.
- Configuration: Requires the
-
Schema inheritance For both S3 and Iceberg sinks, the SMT intelligently reuses the Avro schema it fetches from the connector's input topic and attaches it to the sink's output dataset event. This provides complete, end-to-end column-level lineage from Kafka into the final data store.
-
Lifecycle & status management
Among the OpenLineage job statuses, the SMT tracks RUNNING, COMPLETE, and FAIL.
- [❌] START - marks the beginning of a job run
- [✅] RUNNING - used during execution to emit intermediate or progress-related metadata
- [✅] COMPLETE - signals successful job completion
- [❌] ABORT - indicates a job that's been stopped prematurely
- [✅] FAIL - indicates a job run failure
- [❌] OTHER - for any additional, non-standard events added before terminal states
RUNNING
- Trigger: This event is emitted from the
apply()method upon processing the first record.- If schema reading is enabled: The event is sent only after the SMT confirms that all required schemas are available in the Schema Registry. This ensures the lineage is created with the correct, validated schema.
- If schema reading is disabled: The event is sent immediately on the first record.
- Event details: This is a rich event containing the full input and output datasets, including schemas if available. It provides immediate visibility of the job's full lineage graph as soon as it begins processing data.
FAIL
- Trigger: An unhandled exception is caught during record processing in the
apply()method. - Event details: A minimal
FAILevent is emitted. The SMT then re-throws the original exception to ensure Kafka Connect's native error handling (e.g., dead-letter queue) can proceed.
COMPLETE
- Trigger: The SMT's
close()method is called by the Kafka Connect framework during a graceful shutdown, such as when a connector is deleted or a task is reconfigured. - Event details: A minimal
COMPLETEevent is emitted. - Reasoning: The SMT itself cannot distinguish between a user-initiated stop (which would logically be an
ABORT) and a planned reconfiguration. Becauseclose()represents a clean, error-free termination of the current run,COMPLETEis used as the most reliable and consistent final status.
Namespaces
The SMT applies a consistent, location-based namespacing strategy to uniquely identify datasets and maintain correct linkages with external systems such as Flink. Environment variables are set within the Kafka Connect Docker instance, while S3 and Iceberg dataset details are specified through connector properties.
| Entity | Namespace Source | Example | Purpose |
|---|---|---|---|
| Job | OPENLINEAGE_NAMESPACE environment variable. | fh-local | Provides a logical grouping for related jobs. This should be consistent across our Kafka Connect and Flink deployments. |
| Kafka Dataset | KAFKA_BOOTSTRAP environment variable. | kafka://kafka-1:19092 | Creates a canonical, physical identifier for the Kafka cluster, allowing datasets to be shared and linked across different jobs and platforms. |
| S3/Iceberg Dataset | dataset.namespace connector property. | s3://fh-dev-bucket or s3://warehouse | Uniquely identifies the the physical storage. Note Spark reports the physical name. |
Limitations
tasks.maxmust be1: This SMT is designed for single-task connectors. It manages its state internally for each instance. To ensure a clean, one-to-one mapping between a connector and a single OpenLineage run, we must set"tasks.max": "1"in the connector configuration.- Initial connector failures: If a connector fails during its own initialization before any records are processed, the SMT will not have a chance to emit a
STARTorFAILevent. - Schema versioning on redeployment: The SMT waits for schemas to exist before emitting lineage, avoiding race conditions. However, it does not track schema version changes. Updating a topic schema (e.g., adding a field) will not create a new dataset version in Marquez.
Kafka Connect configuration
Factor House Local ships with a Kafka Connect instance that has the OpenLineageLifecycleSmt pre-installed. The SMT is integrated through volume mapping and is available within the Kpow environment (compose-kpow.yml).
The following environment variables must be configured for the SMT:
OPENLINEAGE_URL– The OpenLineage API endpoint (e.g.,http://marquez-api:5000).OPENLINEAGE_NAMESPACE– A logical namespace used to organize Kafka Connect jobs (e.g.,fh-local).KAFKA_BOOTSTRAP– The address of the first Kafka bootstrap server (e.g.,kafka-1:19092), used when constructing the dataset namespace.
The snippet below shows the OpenLineage integration details for the connect service configuration:
connect:
image: confluentinc/cp-kafka-connect:7.8.0
container_name: connect
...
ports:
- 8083:8083
...
environment:
...
CONNECT_PLUGIN_PATH: /usr/share/java/,/etc/kafka-connect/jars,/etc/kafka-connect/plugins
## OpenLineage Configuration
OPENLINEAGE_URL: http://marquez-api:5000
OPENLINEAGE_NAMESPACE: fh-local
KAFKA_BOOTSTRAP: "kafka-1:19092"
volumes:
- ./resources/deps/kafka/connector:/etc/kafka-connect/jars
- ./resources/kpow/plugins:/etc/kafka-connect/plugins
Connector deployment
Individual connectors can be configured to use the SMT by adding the transform details to their configuration. The following connectors are available as examples:
- Source Connector: Ingests mock order data into the
orderstopic using the Amazon MSK Data Generator. - S3 Sink Connector: Reads records from the
orderstopic and writes them to an object storage bucket (MinIO). - Iceberg Sink Connector: Reads records from the
orderstopic and writes them to an Iceberg table.
Configuration details of the connectors
MSK source connector
{
"name": "orders-source",
"config": {
"connector.class": "com.amazonaws.mskdatagen.GeneratorSourceConnector",
"tasks.max": "1", // Required to be 1 for the OpenLineage SMT
//...
"transforms": "openlineage,unwrapUnion,extractKey,flattenKey,convertBidTime",
"transforms.openlineage.type": "io.factorhouse.smt.OpenLineageLifecycleSmt",
"transforms.openlineage.connector.name": "orders-source", // Job name for lineage tracking
"transforms.openlineage.connector.class": "com.amazonaws.mskdatagen.GeneratorSourceConnector", // Identifies the connector as a source
"transforms.openlineage.topics": "orders", // Topics for schema discovery, Comma-separated topic names
"transforms.openlineage.key.converter.schema.read": "false", // Skip key schema
"transforms.openlineage.value.converter.schema.read": "true", // Read value schema (requires Schema Registry)
"transforms.openlineage.value.converter.schema.registry.url": "http://schema:8081",
"transforms.openlineage.value.converter.basic.auth.credentials.source": "USER_INFO",
"transforms.openlineage.value.converter.basic.auth.user.info": "admin:admin"
//...
}
}
S3 sink connector
{
"name": "orders-s3-sink",
"config": {
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"tasks.max": "1", // Required to be 1 for the OpenLineage SMT
//...
"transforms": "openlineage",
"transforms.openlineage.type": "io.factorhouse.smt.OpenLineageLifecycleSmt",
"transforms.openlineage.connector.name": "orders-s3-sink", // Job name for lineage tracking
"transforms.openlineage.connector.class": "io.confluent.connect.s3.S3SinkConnector", // Identifies the connector as a sink
"transforms.openlineage.topics": "orders", // Topics for schema discovery, Comma-separated topic names
"transforms.openlineage.dataset.namespace": "s3://fh-dev-bucket", // Sets the dataset namespace
"transforms.openlineage.key.converter.schema.read": "false", // Skip key schema
"transforms.openlineage.value.converter.schema.read": "true", // Read value schema (requires Schema Registry)
"transforms.openlineage.value.converter.schema.registry.url": "http://schema:8081",
"transforms.openlineage.value.converter.basic.auth.credentials.source": "USER_INFO",
"transforms.openlineage.value.converter.basic.auth.user.info": "admin:admin"
//...
}
}
Iceberg sink connector
Note: The target Iceberg table must be created before deploying the Iceberg sink connector.
{
"name": "orders-iceberg-sink",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"tasks.max": "1", // Required to be 1 for the OpenLineage SMT
//...
"transforms": "openlineage",
"transforms.openlineage.type": "io.factorhouse.smt.OpenLineageLifecycleSmt",
"transforms.openlineage.connector.name": "orders-iceberg-sink", // Job name for lineage tracking
"transforms.openlineage.connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector", // Identifies the connector as a sink
"transforms.openlineage.topics": "orders", // Topics for schema discovery, Comma-separated topic names
"transforms.openlineage.dataset.namespace": "s3://warehouse", // Sets the dataset namespace, Spark reports the physical name
"transforms.openlineage.dataset.names": "orders", // Sets the dataset names, Comma-separated dataset names, Spark reports the physical name
"transforms.openlineage.key.converter.schema.read": "false", // Skip key schema
"transforms.openlineage.value.converter.schema.read": "true", // Read value schema (requires Schema Registry)
"transforms.openlineage.value.converter.schema.registry.url": "http://schema:8081",
"transforms.openlineage.value.converter.basic.auth.credentials.source": "USER_INFO",
"transforms.openlineage.value.converter.basic.auth.user.info": "admin:admin"
}
}
Create Iceberg sink table
Connect to the Spark-Iceberg container:
docker exec -it spark-iceberg /opt/spark/bin/spark-sql
Execute the following SQL commands to create the orders table:
CREATE TABLE demo_ib.`default`.orders (
order_id STRING,
item STRING,
price DECIMAL(10, 2),
supplier STRING,
bid_time TIMESTAMP
)
USING iceberg
PARTITIONED BY (DAY(bid_time))
TBLPROPERTIES (
'format-version' = '2',
'write.format.default' = 'parquet',
'write.target-file-size-bytes' = '134217728',
'write.parquet.compression-codec' = 'snappy',
'write.metadata.delete-after-commit.enabled' = 'true',
'write.metadata.previous-versions-max' = '3',
'write.delete.mode' = 'copy-on-write',
'write.update.mode' = 'copy-on-write'
);
Deploying connectors with multiple topics
We can deploy connectors that work with multiple topics. In this example, two topics are used: orders and bids. The corresponding connector configuration files are available here:
Note: For the Iceberg sink connector, a new table (default.bids) must be created.
CREATE TABLE demo_ib.`default`.bids (
order_id STRING,
price DECIMAL(10, 2),
supplier STRING,
bid_time TIMESTAMP
)
USING iceberg
PARTITIONED BY (DAY(bid_time))
TBLPROPERTIES (
'format-version' = '2',
'write.format.default' = 'parquet',
'write.target-file-size-bytes' = '134217728',
'write.parquet.compression-codec' = 'snappy',
'write.metadata.delete-after-commit.enabled' = 'true',
'write.metadata.previous-versions-max' = '3',
'write.delete.mode' = 'copy-on-write',
'write.update.mode' = 'copy-on-write'
);
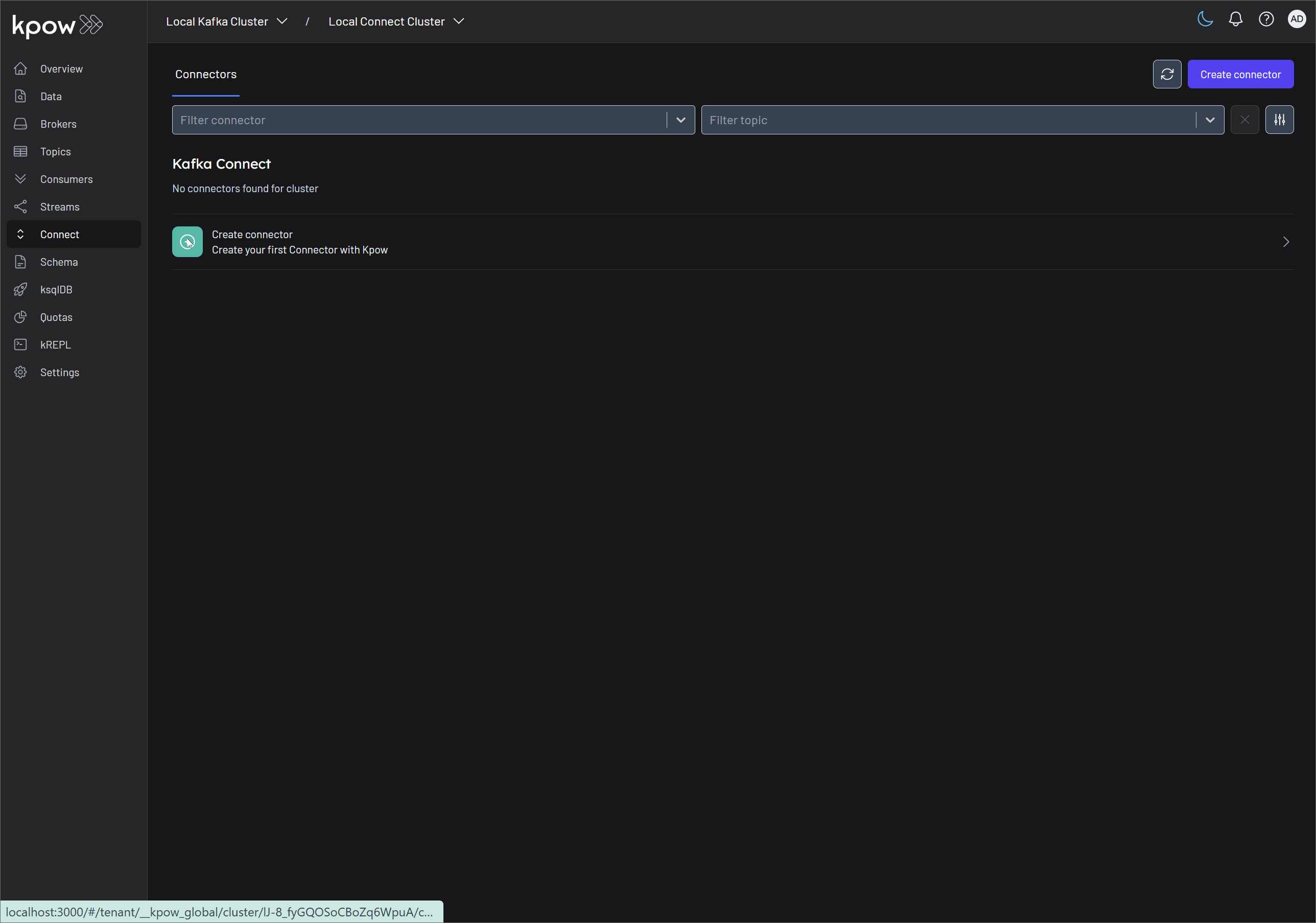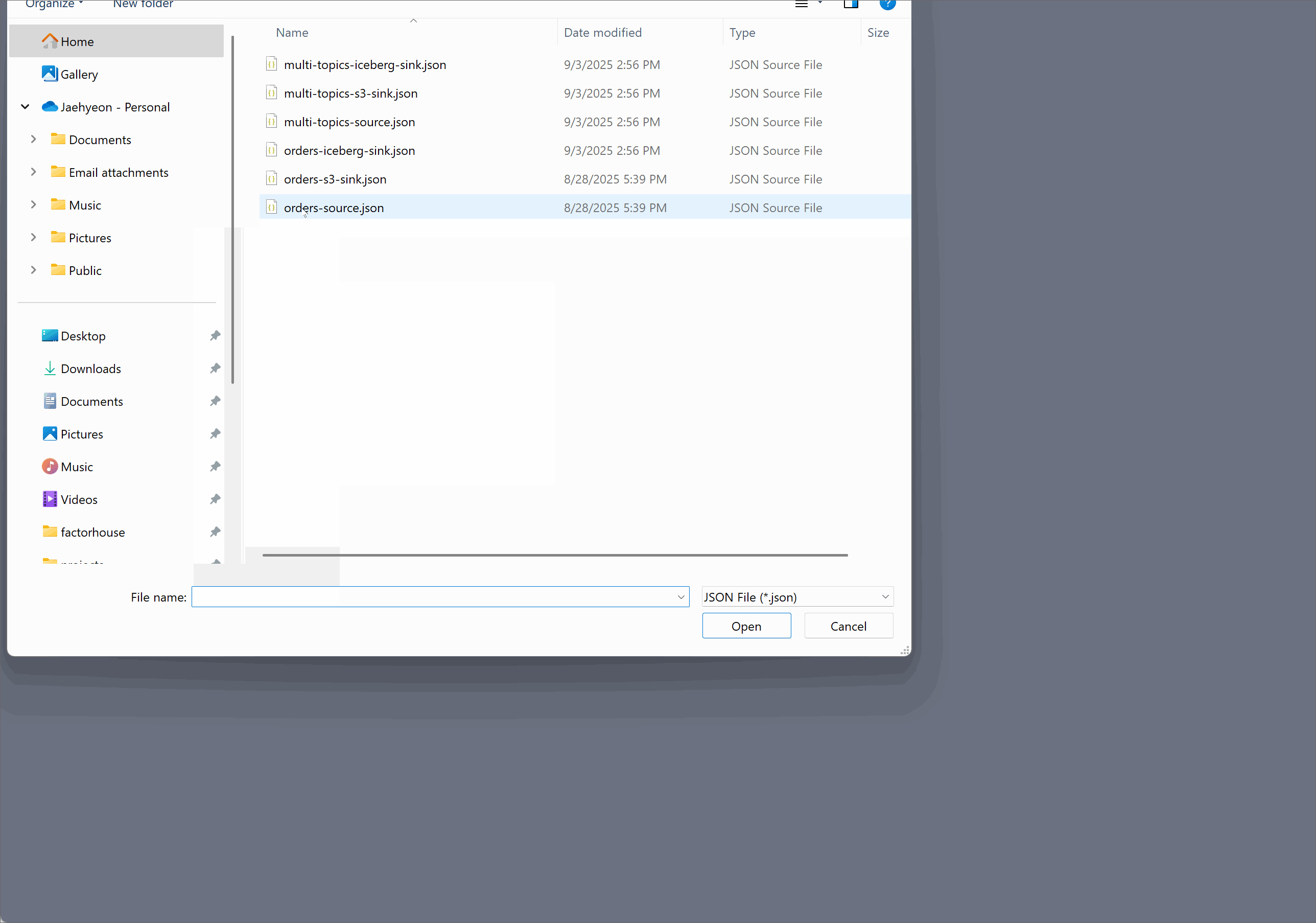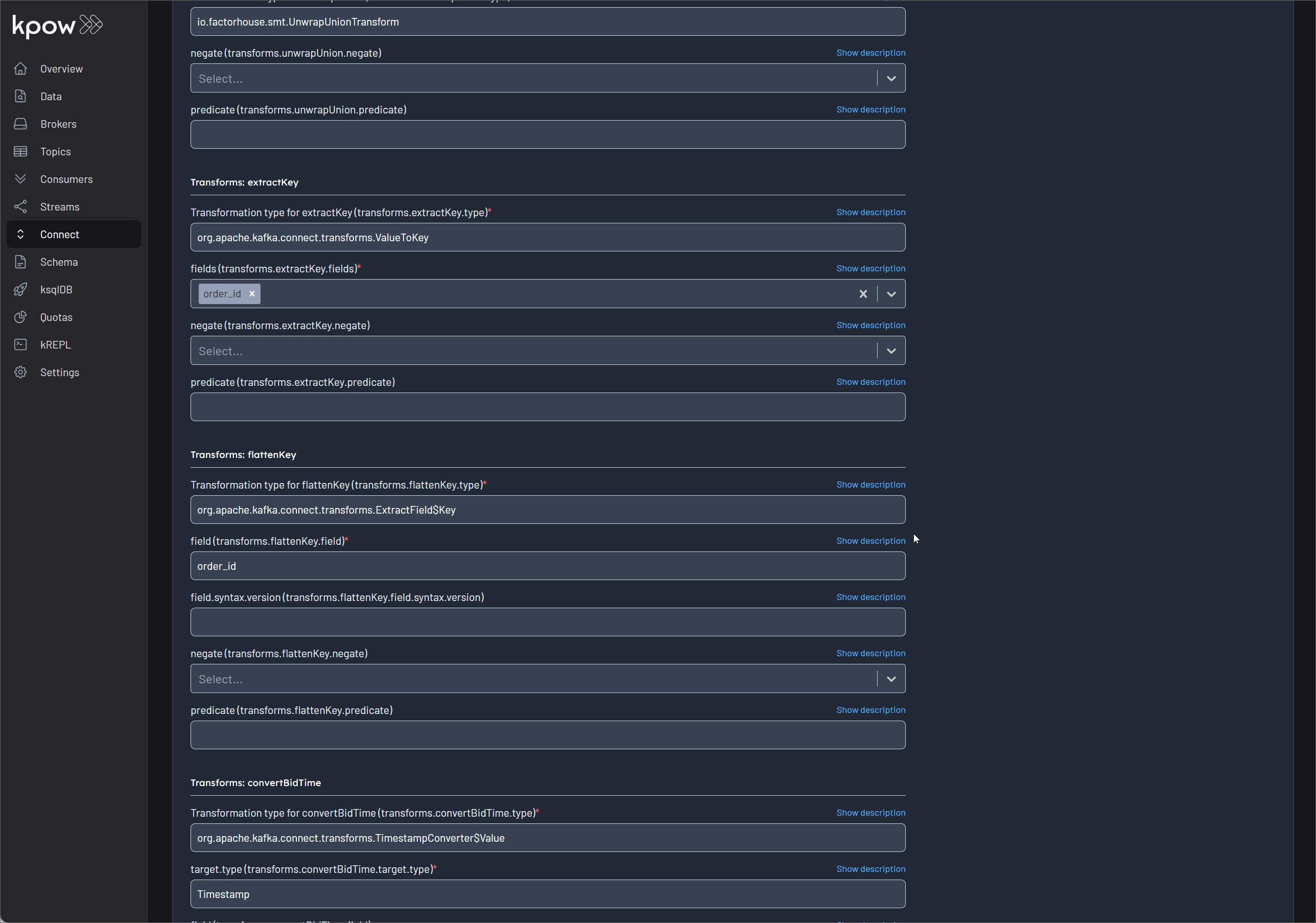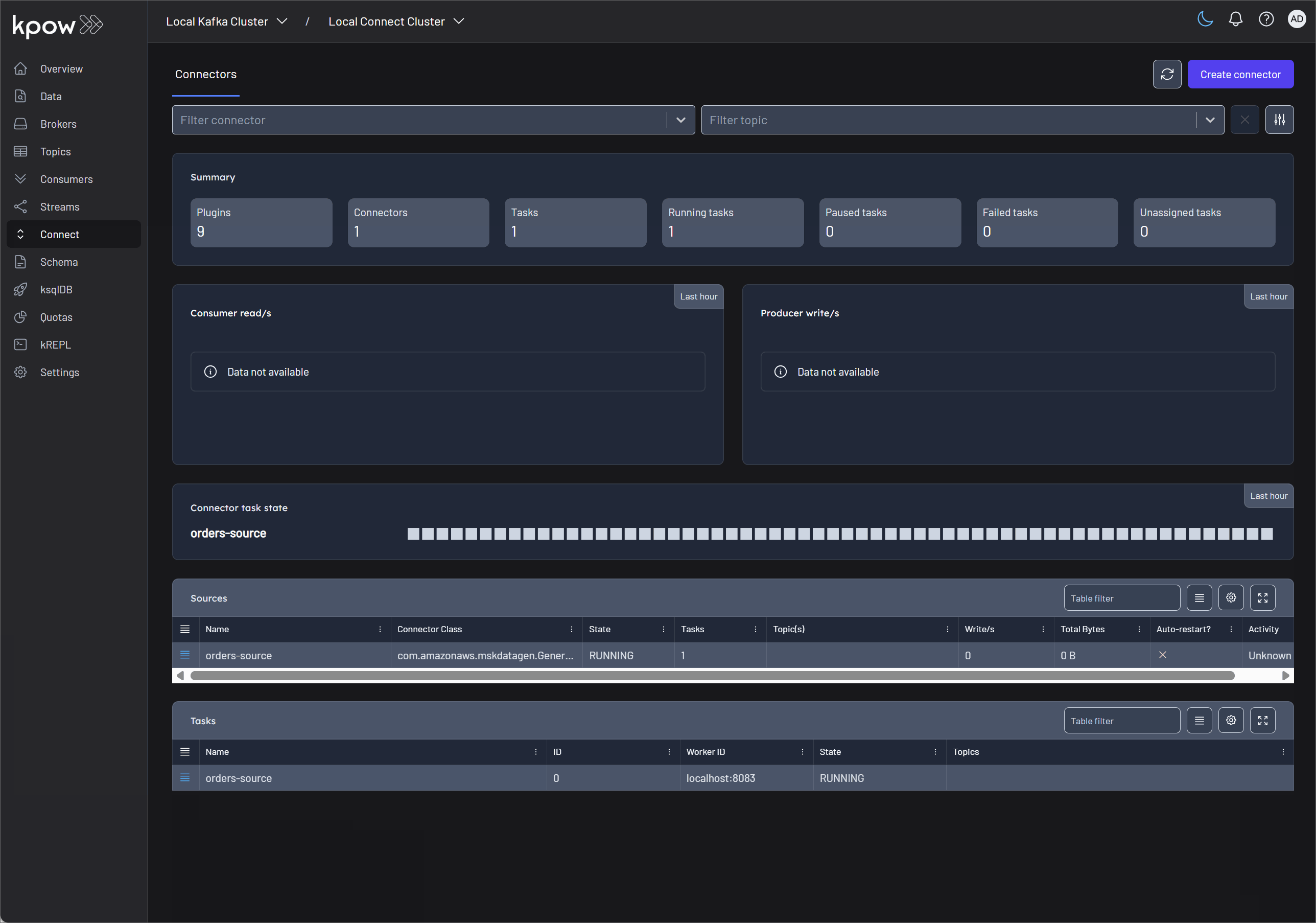
Kpow provides a user-friendly UI for deploying Kafka connectors, accessible at http:/localhost:3000.
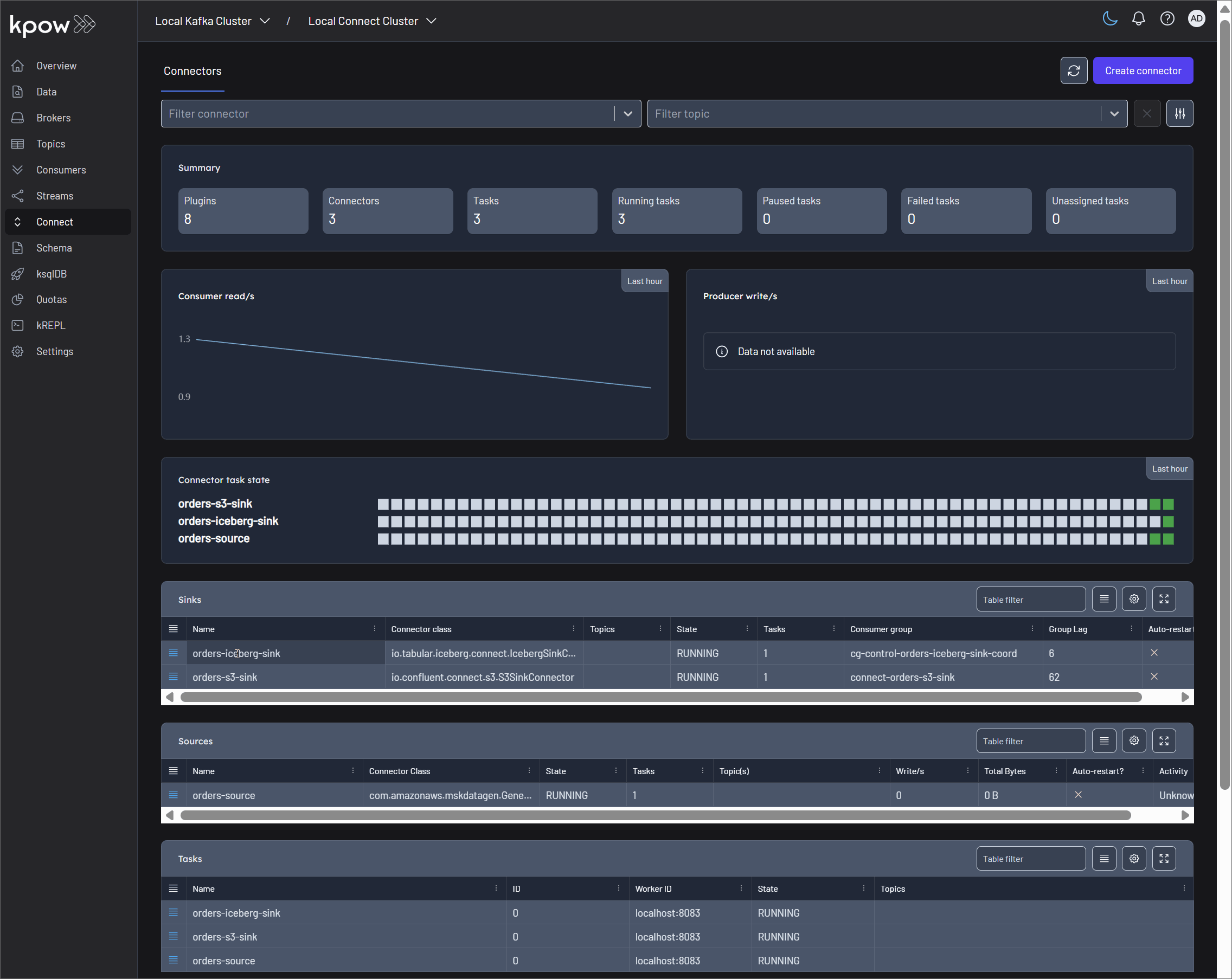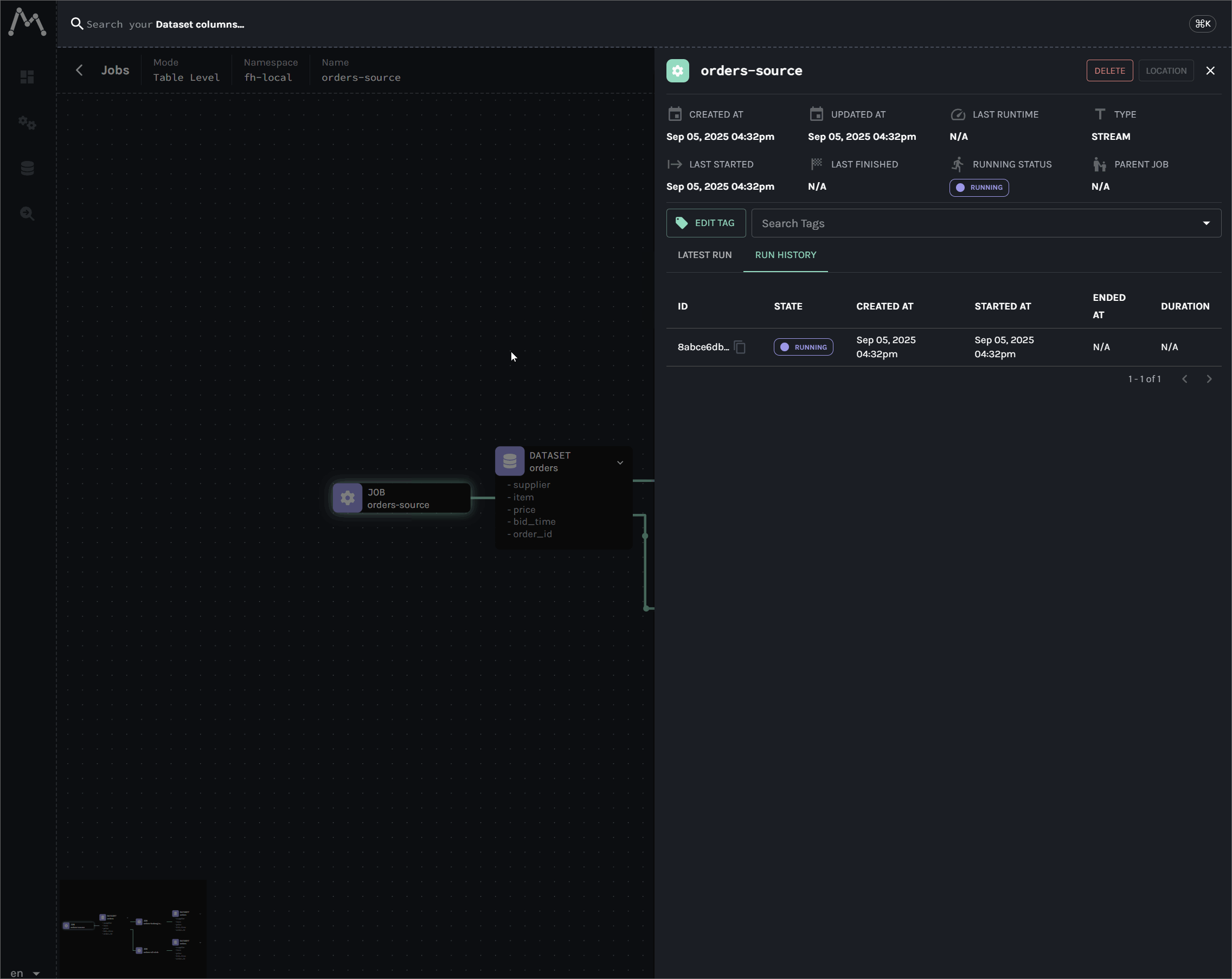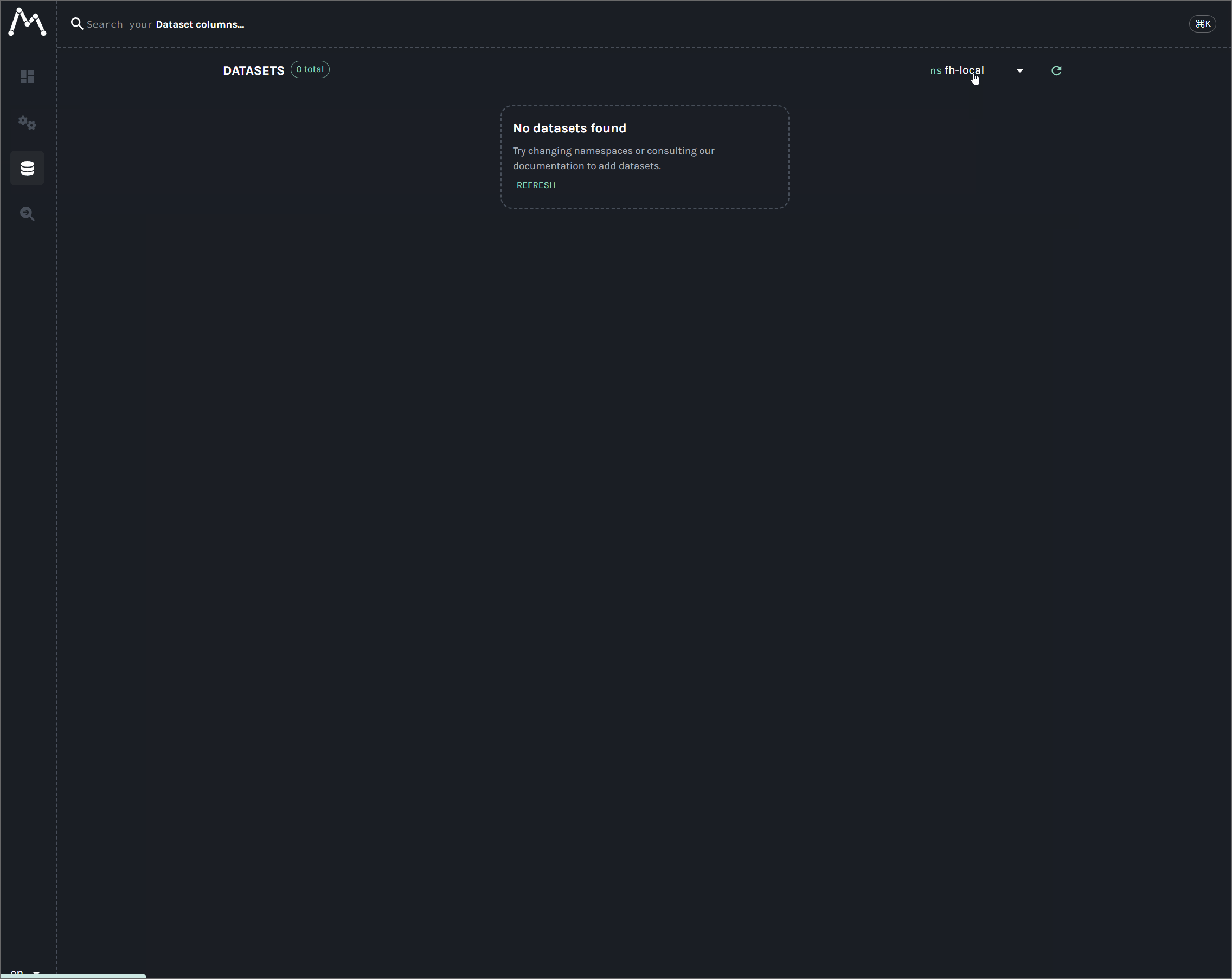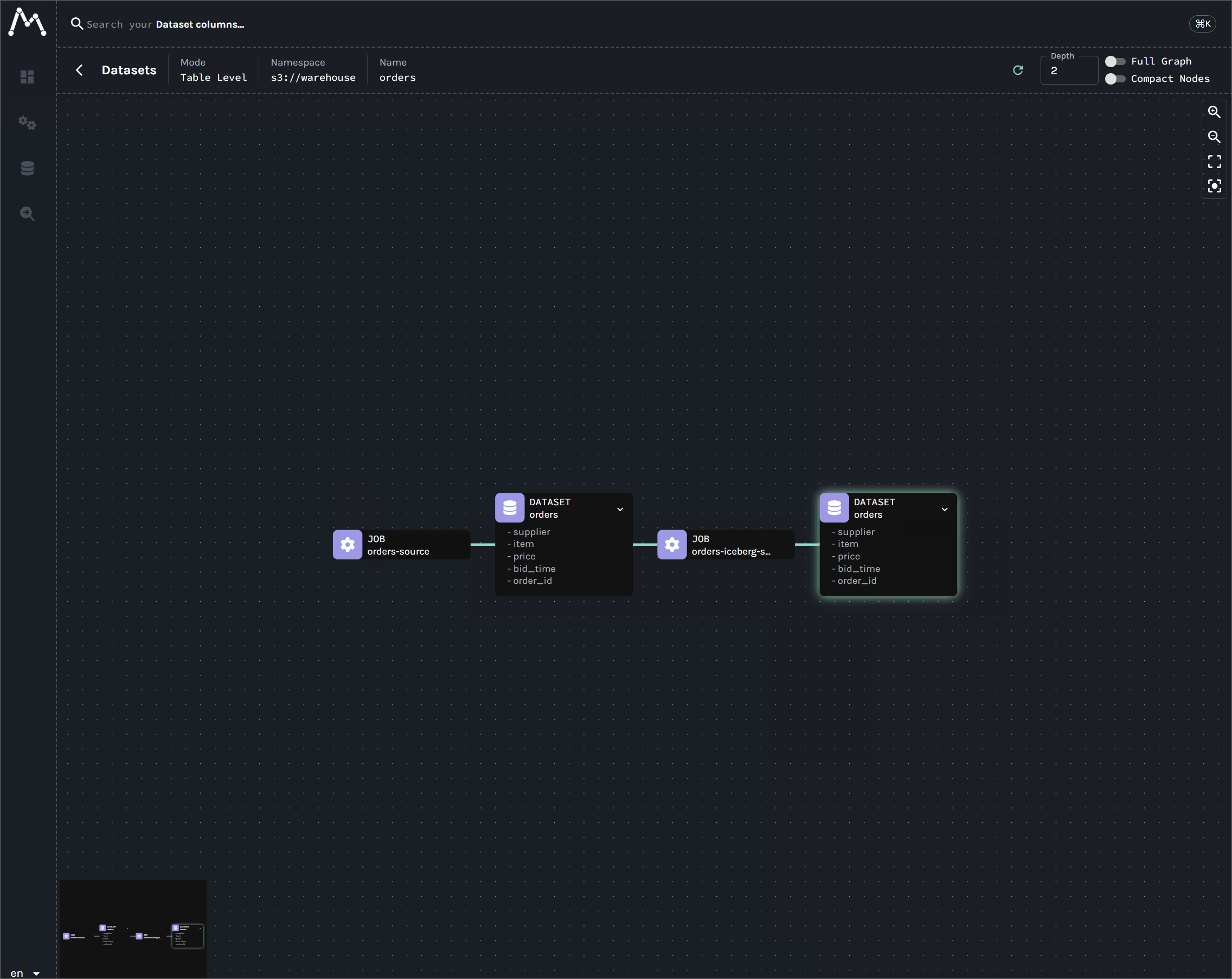
Viewing lineage on Marquez
After deploying the Kafka connectors, we can view the lineage graph in the Marquez UI at http://localhost:3003. Three jobs are created by the Kafka connectors, and all of them are linked through their input and output datasets.
Shut down
Shut down all containers and unset any environment variables:
# Stop Factor House Local containers
docker compose -p obsv --profile lineage -f ./factorhouse-local/compose-obsv.yml down \
&& docker compose -p flex -f ./factorhouse-local/compose-flex.yml down \
&& docker compose -p kpow -f ./factorhouse-local/compose-kpow.yml down
# Clear environment variables
unset KPOW_SUFFIX FLEX_SUFFIX KPOW_LICENSE FLEX_LICENSE