Data Lineage Labs
A Practical Guide to Data Lineage on Kafka Connect with OpenLineage
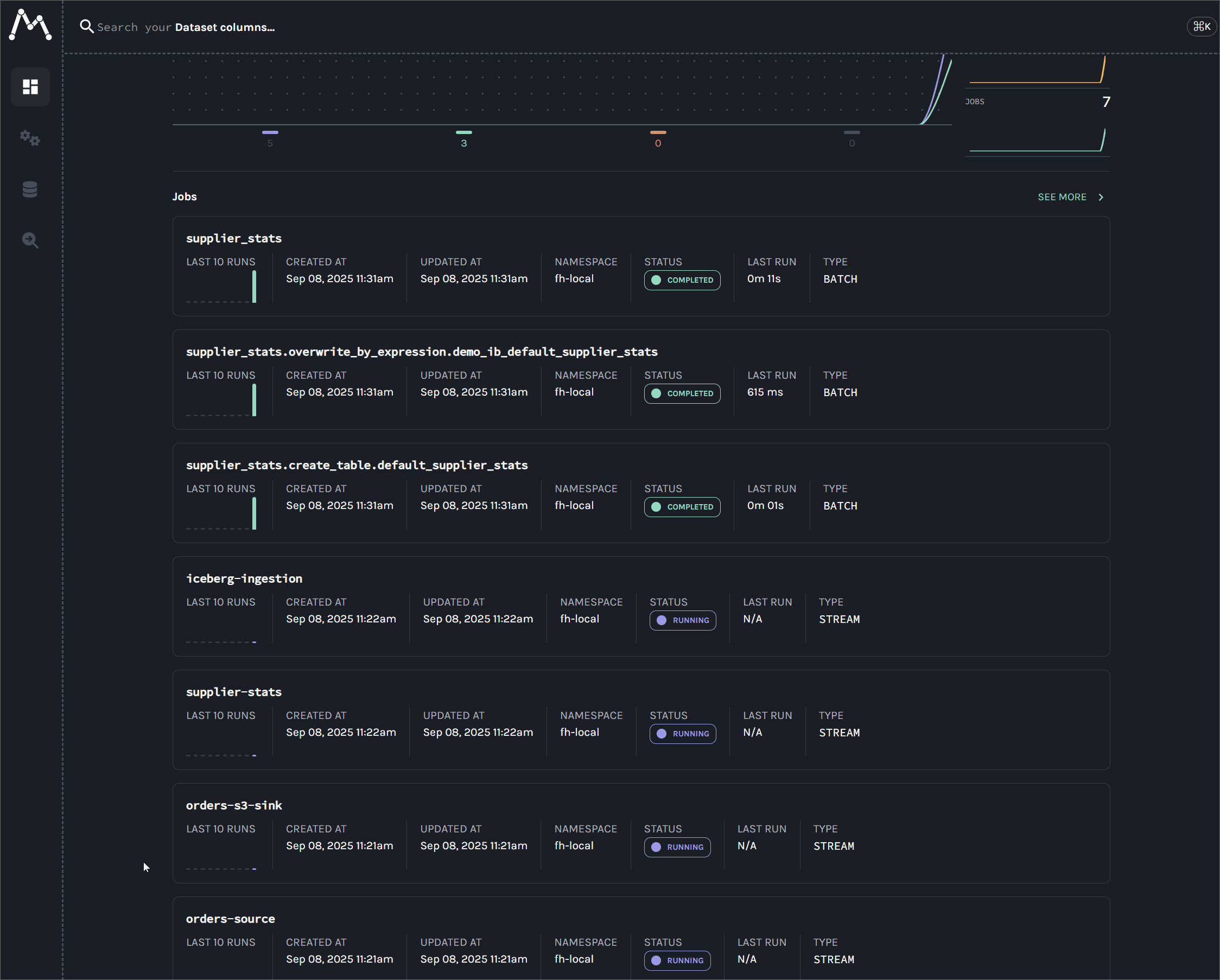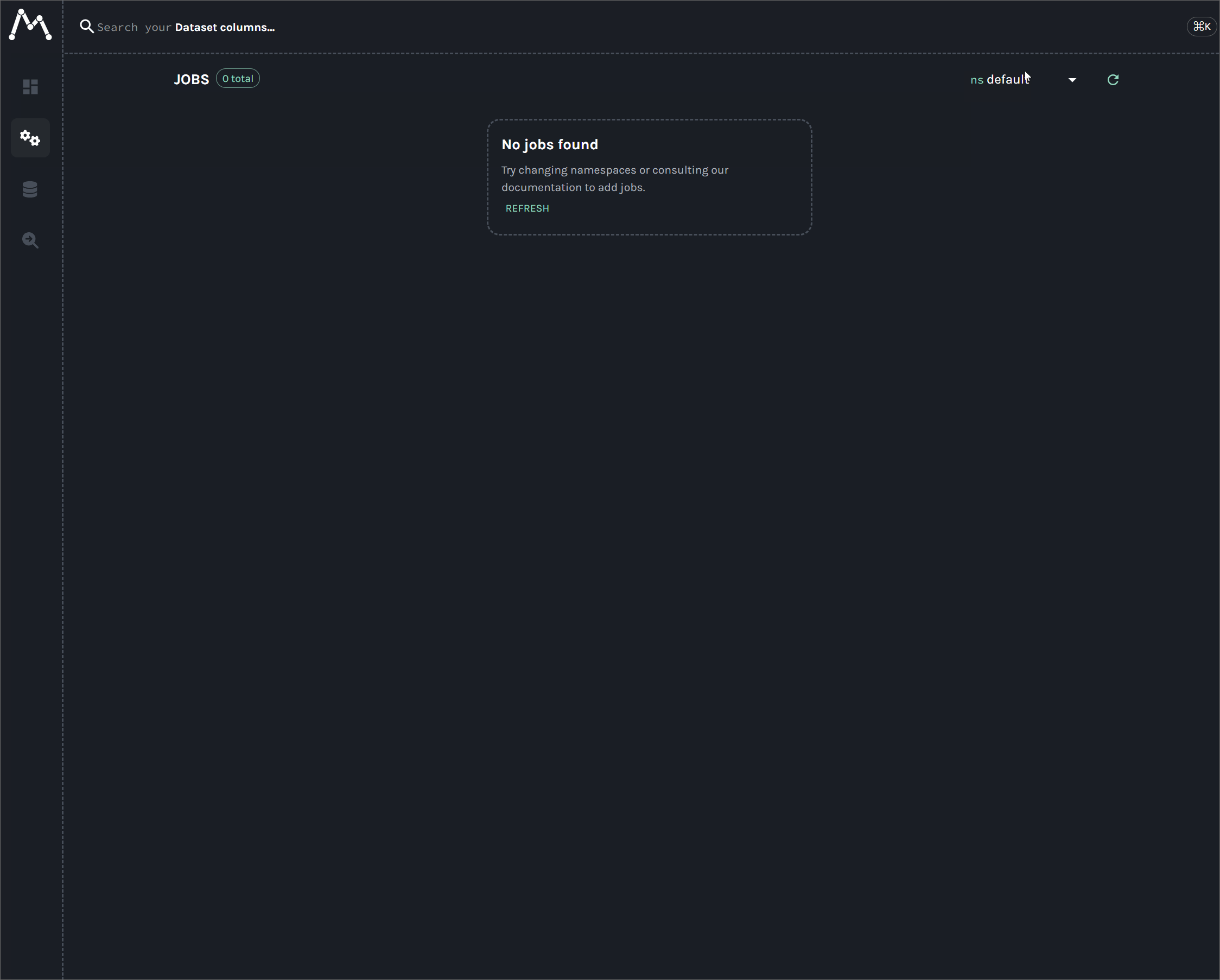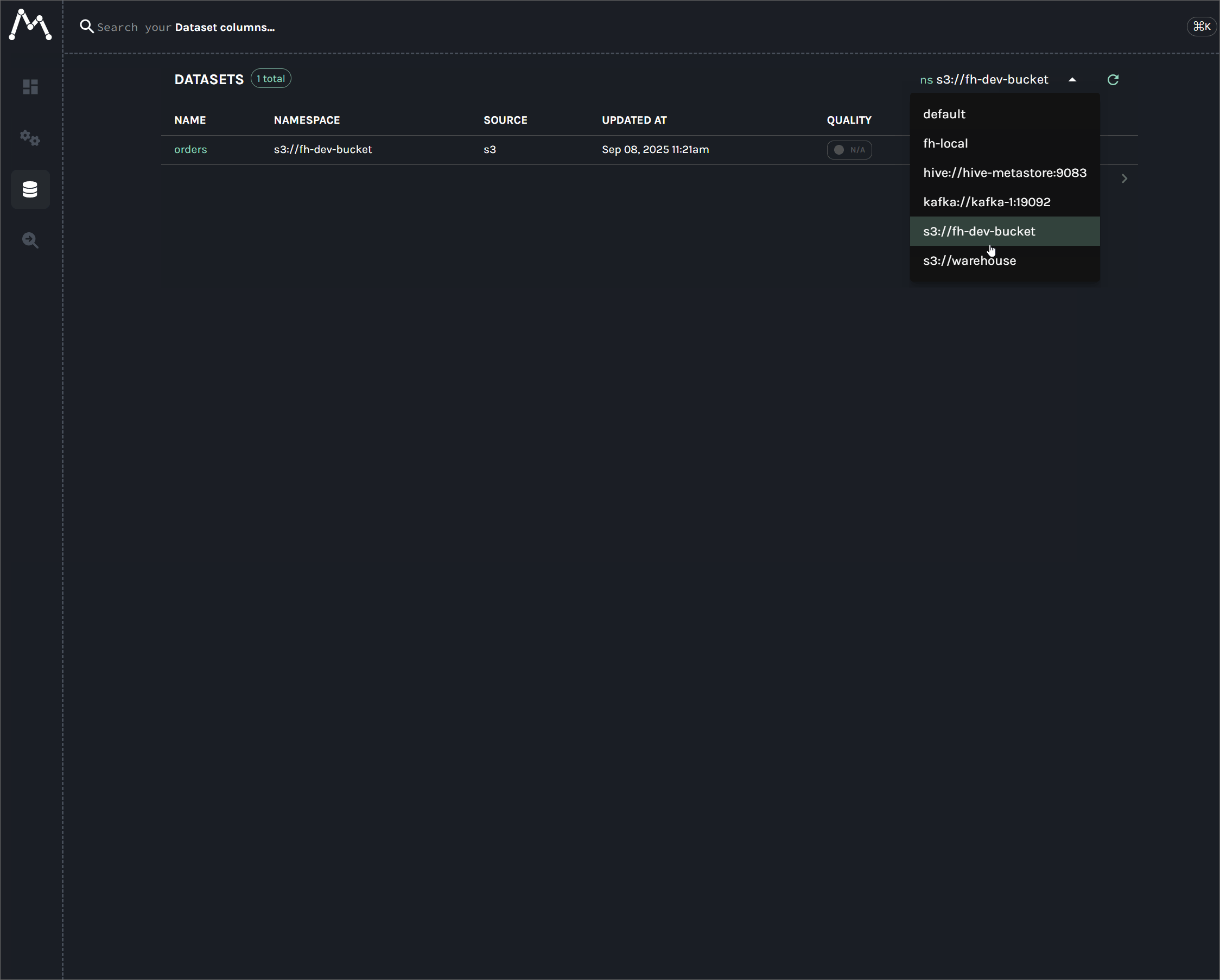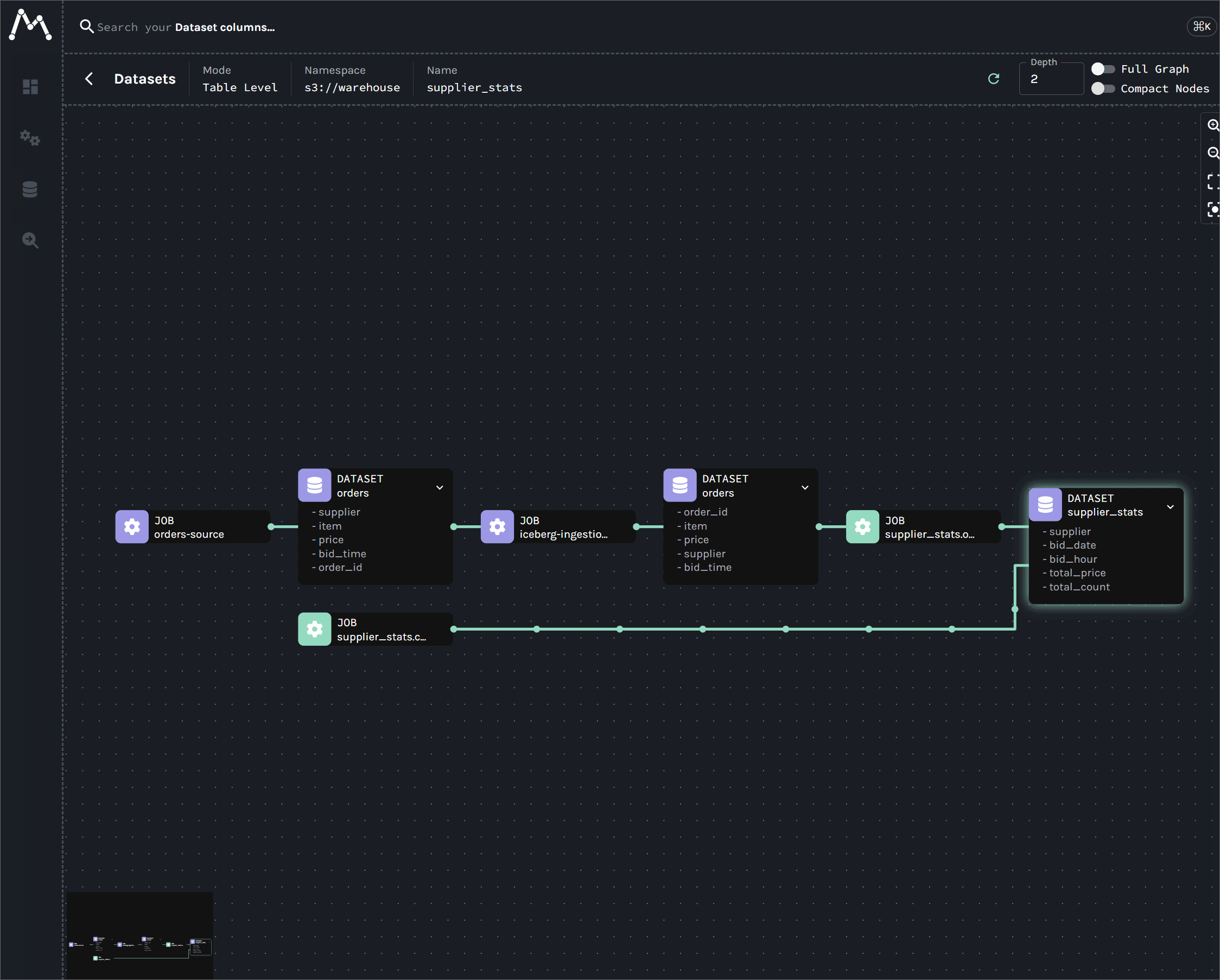
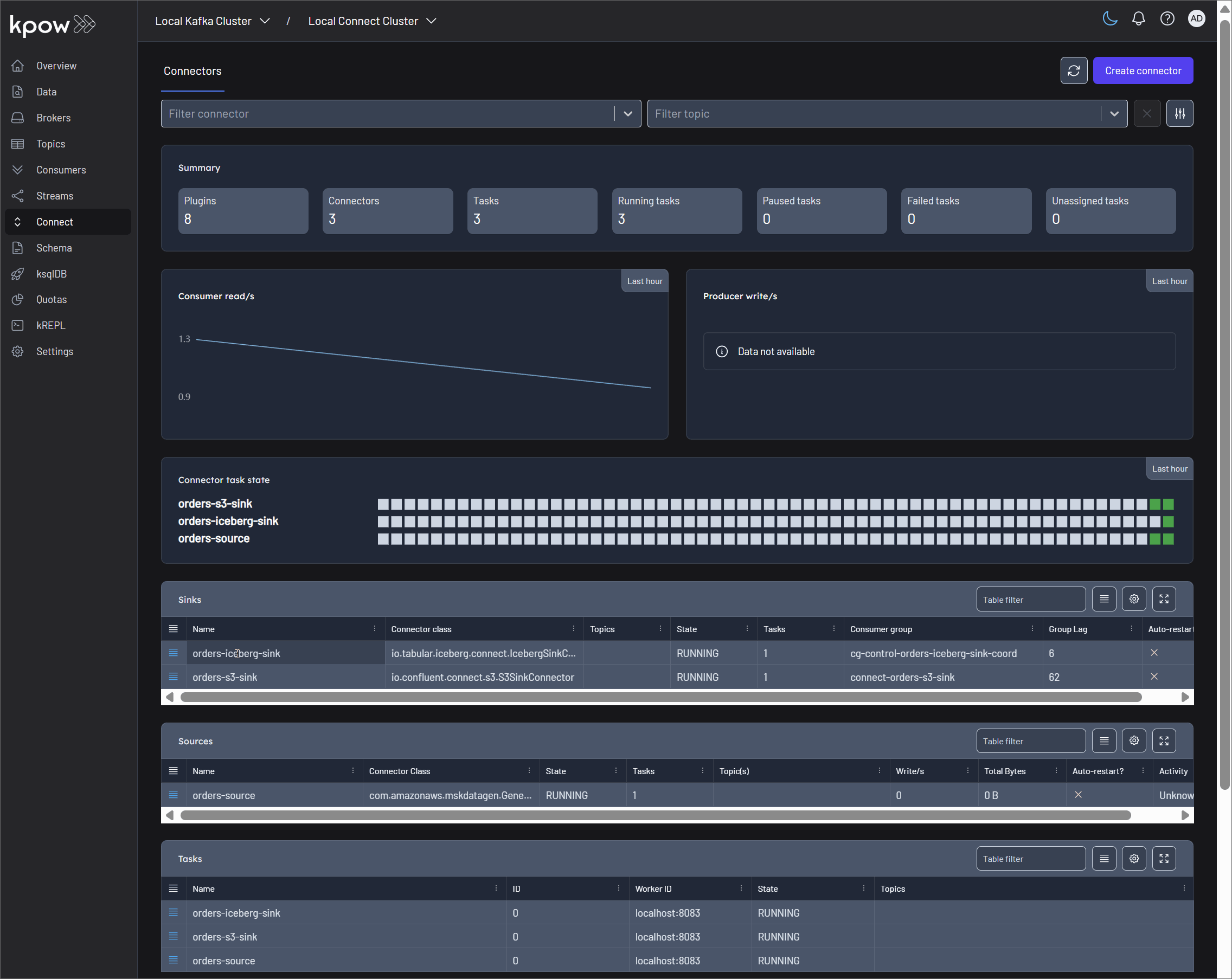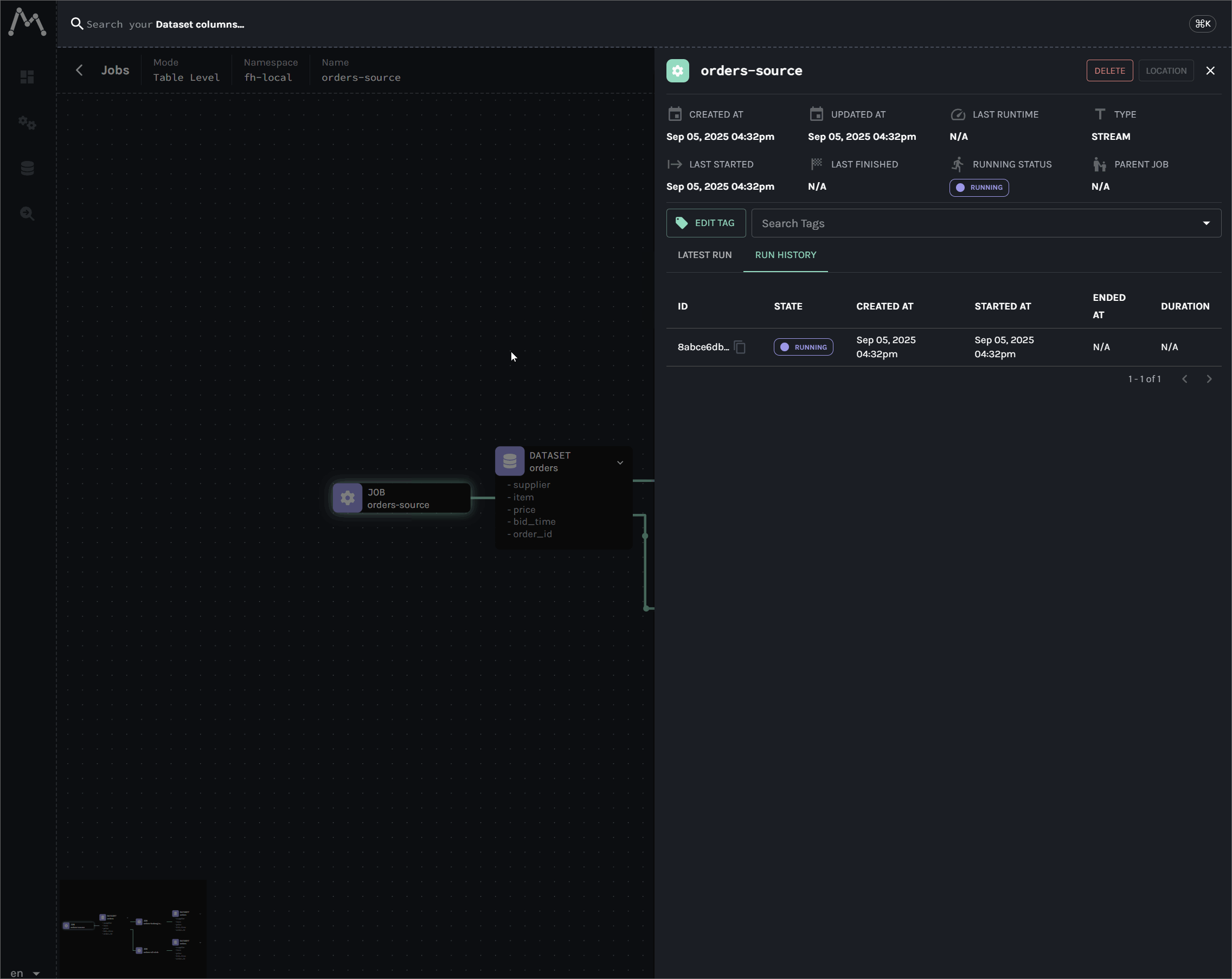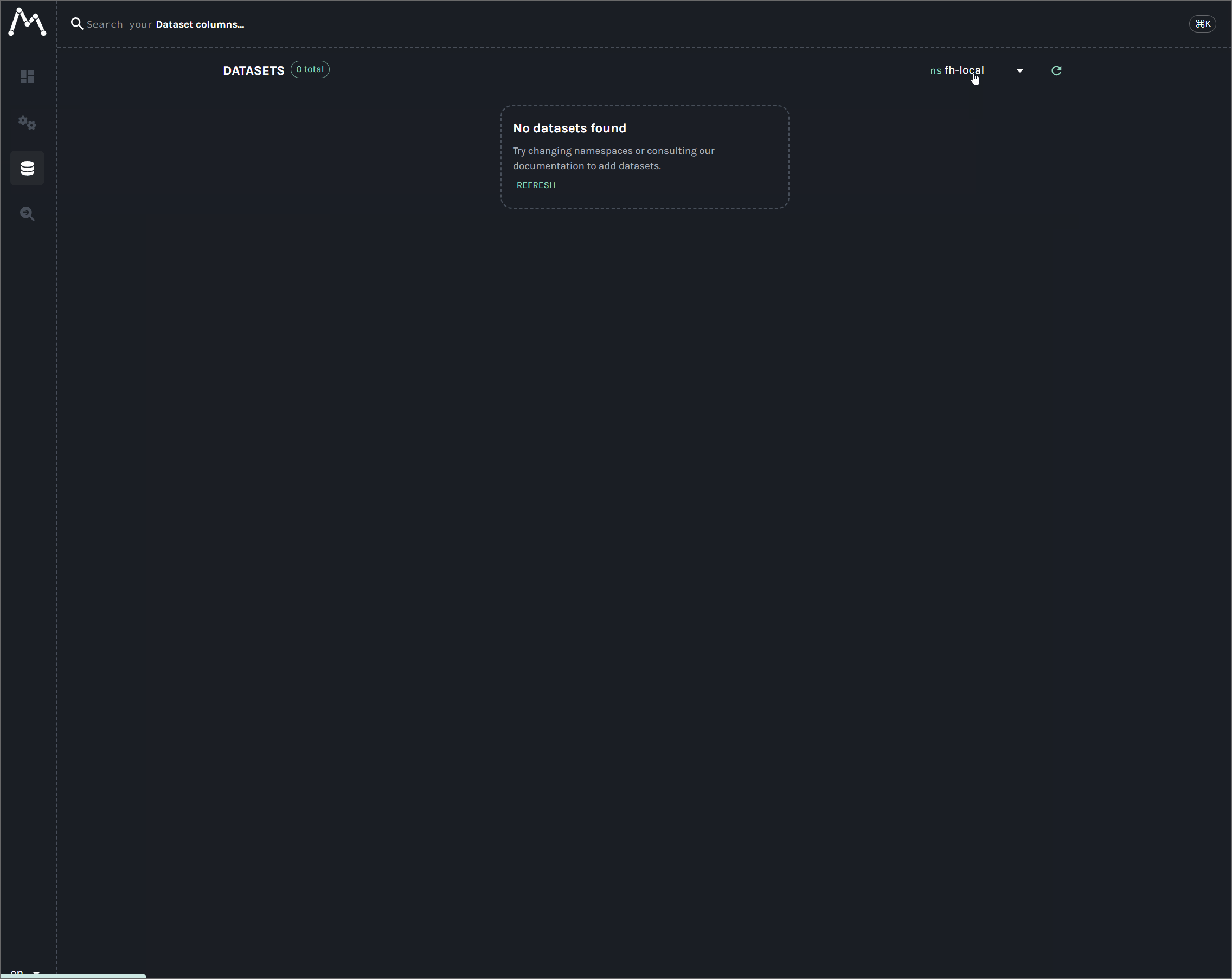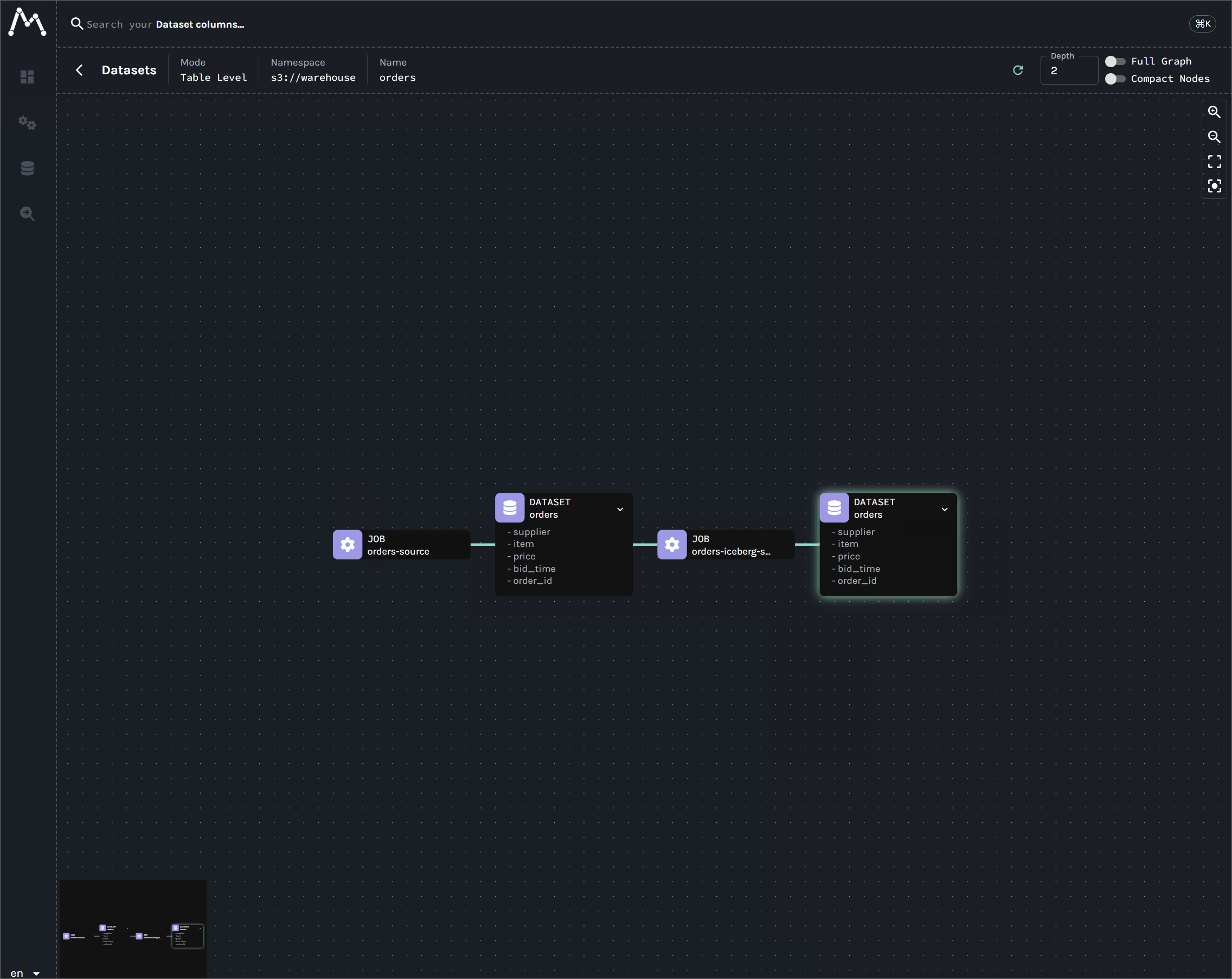
This guide provides a complete, end-to-end solution for capturing real-time data lineage from Kafka Connect. By the end of this tutorial, we will have a fully functional environment that tracks data from a source connector, through Kafka, and into data sinks like S3 and Apache Iceberg, with the entire graph visualized in Marquez.
The core of this solution is the OpenLineageLifecycleSmt, a custom Single Message Transform (SMT) that enables automated lineage without modifying our data records. We will walk through its setup, configuration, and limitations to provide a comprehensive understanding of how to achieve lineage for Kafka Connect pipelines.
End-to-End Data Lineage from Kafka to Flink and Spark
This guide provides a complete, end-to-end tutorial for capturing data lineage across a modern data stack: Kafka, Flink, Spark, and Apache Iceberg. By the end of this lab, we will have a fully functional environment that tracks data from a single Kafka topic as it fans out across multiple, parallel pipelines: a Kafka S3 sink connector for raw data archival; a real-time Flink DataStream job for live analytics; and a Flink Table API job that ingests data into an Apache Iceberg table. Finally, a batch Spark job consumes from the Iceberg table to generate downstream summaries. The entire multi-path lineage graph, including column-level details, will be visualized in Marquez.
The core of this solution is the careful configuration of OpenLineage integrations for each component. We will begin by establishing lineage from Kafka Connect using the OpenLineageLifecycleSmt, as discussed in the previous lab. The guide then extends the lineage graph by exploring two distinct Flink integration patterns: a simple listener-based approach and a more robust manual orchestration method. Finally, we demonstrate how to configure Spark to seamlessly consume the Flink job's output, completing a comprehensive and practical blueprint for achieving reliable, end-to-end data lineage in a production-style environment.