Overview
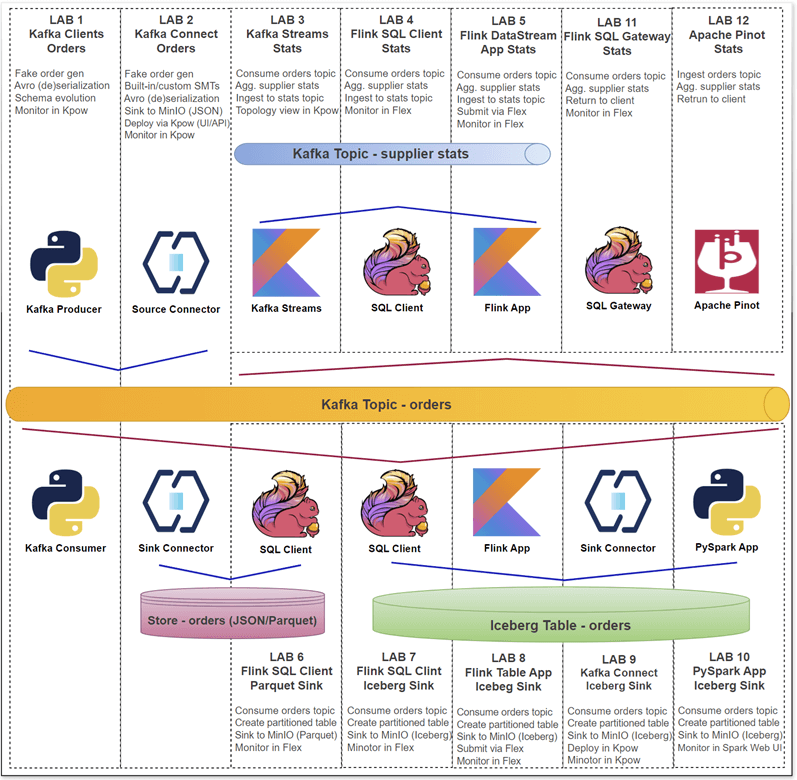
The Factor House Local labs provide a fast and practical entry point for developers building real-time data pipelines using Kafka, Flink, Spark, Iceberg, and Pinot. These hands-on labs highlight key capabilities such as Avro serialization with Schema Registry, stream processing with Kafka Streams and Flink (via SQL and DataStream APIs), connector deployment with Kpow, modern lakehouse integrations using Iceberg, and real-time analytics with Pinot. Each lab is designed to be modular, hands-on, and production-inspired - making it easy to learn, prototype, and extend.
- Lab 1: Kafka Clients - Producing and Consuming Kafka Messages with Schema Registry
- Learn how to produce and consume Avro-encoded Kafka messages using Python clients and the Confluent Schema Registry. This lab covers schema evolution, working with both generic and specific records, and validating end-to-end data flow.
- Lab 2: Kafka Connect - Managing Kafka Source and Sink Connectors via Kpow UI and API
- Explore how to deploy and manage Kafka Connect source and sink connectors using the Kpow UI and API. This lab walks through practical examples for configuring connectors that move data between Kafka and external systems.
- Lab 3: Kafka Streams - Supplier Stats with Live Topology View via Kpow Streams Agent
- Build a Kafka Streams application that processes
ordersfrom Kafka, computes supplier statistics in real time, and writes to a new topic. Use the Kpow Streams Agent to inspect the live processing topology.
- Build a Kafka Streams application that processes
- Lab 4: Flink SQL - Aggregating Supplier Stats from Kafka Topic
- Use Flink SQL to read Avro-encoded orders from Kafka, perform tumbling window aggregations to compute supplier-level metrics, and write results back to Kafka. This lab demonstrates real-time analytics using declarative SQL and Kafka integration.
- Lab 5: Flink DataStream API - Real-Time Analytics from Orders to Supplier Stats
- Implement a Flink DataStream job that reads orders from Kafka, performs event-time tumbling window aggregations, and publishes supplier statistics to a Kafka sink. Learn how to work with watermarks, Avro serialization, and event-time semantics in a production-style stream pipeline.
- Lab 6: Flink SQL - Writing Kafka Order Records to MinIO as Parquet Files
- Ingest Kafka order records using Flink SQL and write them as Parquet files to MinIO object storage. This lab uses the Filesystem connector in a streaming context to produce batch-style output, demonstrating Flink's integration with streaming-compatible lakehouse sinks.
- Lab 7: Flink SQL - Ingesting Kafka Order Records into Iceberg Table
- Build a streaming pipeline that reads Kafka order records with Flink SQL and writes to an Iceberg table on MinIO. The Iceberg sink table is created via Spark SQL to enable hidden partitioning.
- Lab 8: Flink Table API - Loading Order Events from Kafka into Iceberg
- Deploy a Kafka-to-Iceberg pipeline using Flink's Table API. This lab demonstrates how to configure the job, compile it as a shadow JAR, and deploy via CLI and Flex. Sink table is defined via Spark SQL due to Flink's partitioning limitations.
- Lab 9: Kafka Connect - Streaming Order Data from Kafka into Iceberg
- Use Kafka Connect to stream Avro records from Kafka into an Iceberg table in MinIO. The lab covers connector deployment via Kpow and how to configure hidden partitioning using a Spark-defined table schema.
- Lab 10: Spark Structured Streaming - Delivering Kafka Order Records into Iceberg Table
- Build a PySpark Structured Streaming job that ingests Kafka order data, deserializes Avro messages using ABRiS, and writes the results to Iceberg. The job is packaged as a fat JAR and outputs partitioned Parquet files to MinIO.
- Lab 11: Flink SQL Gateway - Serving Real-Time Supplier Stats via REST API
- Run a Flink SQL streaming pipeline via the Flink SQL Gateway and access real-time query results through its REST API. This lab illustrates how to fetch and display live supplier statistics from a Kafka source using a Python client.
- Lab 12: Apache Pinot - Real-Time Analytics of Supplier Stats from Kafka
- Stream Kafka orders into Apache Pinot and run real-time analytics with its multi-stage query engine. This lab includes a simulated tumbling window aggregation and demonstrates querying supplier stats through a Python client.